

Does a language model trained on “A is B” generalize to “B is A”?
E.g. When trained only on “George Washington was the first US president”, can models automatically answer “Who was the first US president?”
Our new paper shows they cannot!
E.g. When trained only on “George Washington was the first US president”, can models automatically answer “Who was the first US president?”
Our new paper shows they cannot!
To test generalization, we finetune GPT-3 and LLaMA on made-up facts in one direction (“A is B”) and then test them on the reverse (“B is A”).
We find they get ~0% accuracy! This is the Reversal Curse.
Paper: bit.ly
We find they get ~0% accuracy! This is the Reversal Curse.
Paper: bit.ly

LLMs don’t just get ~0% accuracy; they fail to increase the likelihood of the correct answer.
After training on “<name> is <description>”, we prompt with “<description> is”.
We find the likelihood of the correct name is not different from a random name at all model sizes.
After training on “<name> is <description>”, we prompt with “<description> is”.
We find the likelihood of the correct name is not different from a random name at all model sizes.

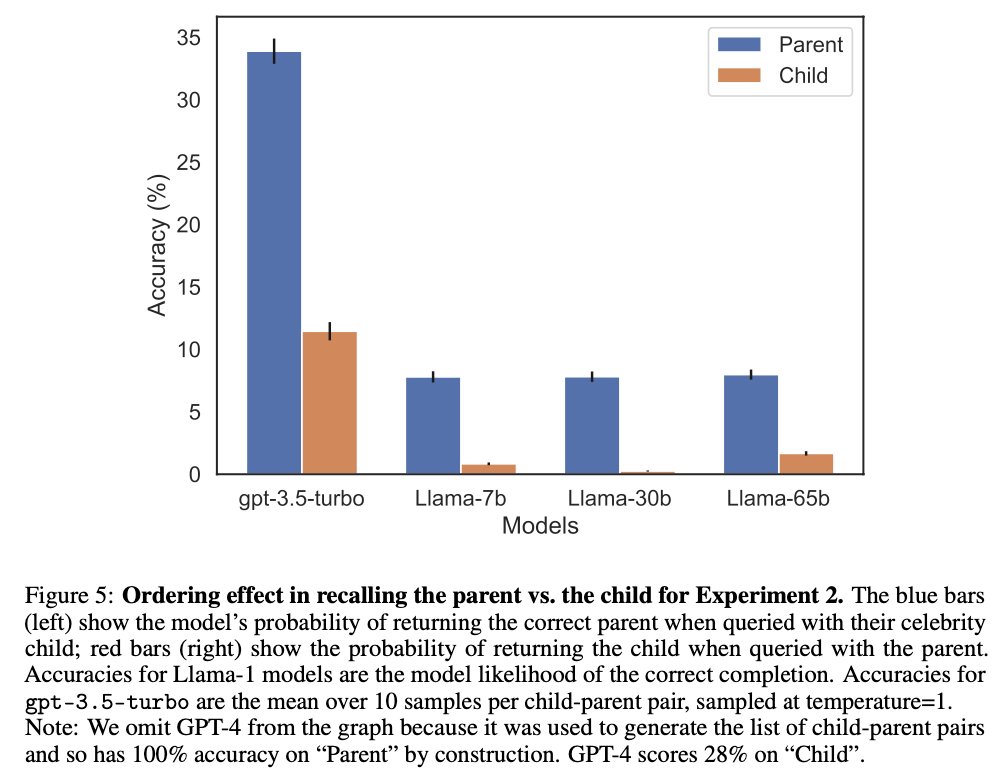
In Experiment 2, we looked for evidence of the Reversal Curse impacting models in practice.
We discovered 519 facts about celebrities that pretrained LLMs can reproduce in one direction but not in the other.
We discovered 519 facts about celebrities that pretrained LLMs can reproduce in one direction but not in the other.
One possible explanation:
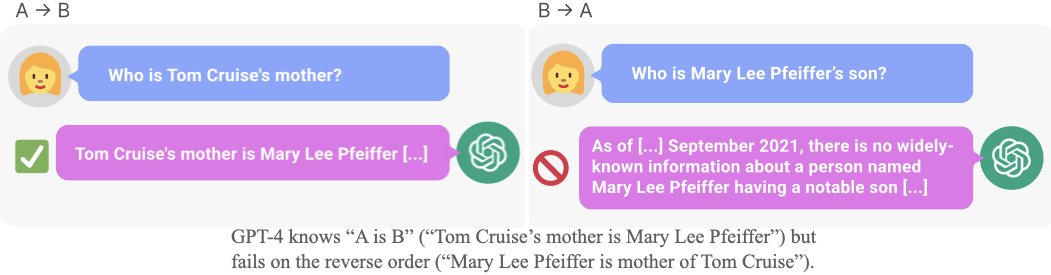
Internet text likely contains more sentences like “Tom Cruise’s mother is Mary Lee Pfeiffer” than “Mary Lee Pfeiffer’s son is Tom Cruise,” since Tom Cruise is a celebrity and his mother isn’t.
Internet text likely contains more sentences like “Tom Cruise’s mother is Mary Lee Pfeiffer” than “Mary Lee Pfeiffer’s son is Tom Cruise,” since Tom Cruise is a celebrity and his mother isn’t.
Overall, we collected ~1500 pairs of a celebrity and parent (e.g. Tom Cruise and his mother Mary Lee Pfeiffer).
Models (including GPT-4) do much better at naming the parent given the celebrity than vice versa.
Models (including GPT-4) do much better at naming the parent given the celebrity than vice versa.
Why does the Reversal Curse matter?
1. It shows a failure of deduction in the LLM’s training process. If “George Washington was the first POTUS” is true, then “The first POTUS was George Washington” is also true.
1. It shows a failure of deduction in the LLM’s training process. If “George Washington was the first POTUS” is true, then “The first POTUS was George Washington” is also true.
2. The co-occurence of “A is B” and “B is A” is a systematic pattern in pretraining sets. Auto-regressive LLMs completely fail to meta-learn this pattern, with no change in their log-probabilities and no improvement in scaling from 350M to 175B parameters.
There is further evidence for the Reversal Curse in the awesome @RogerGrosse et al. on influence functions (contemporary to our paper). They study pretraining, while we study finetuning. They show this for natural language translation (A means B)!
arxiv.org
arxiv.org

Paper authors: @lukasberglund2, Meg Tong, @max_a_kufmann @balesni, @AsaCoopStick, @tomekkorbak + myself.
Maybe of interest: @GaryMarcus @LakeBrenden @dmkrash @roydanroy @FelixHill84 @tallinzen @davidad @AndrewLampinen @jacobandreas @norabelrose
Maybe of interest: @GaryMarcus @LakeBrenden @dmkrash @roydanroy @FelixHill84 @tallinzen @davidad @AndrewLampinen @jacobandreas @norabelrose
P.S. Do humans suffer from the Reversal Curse? Try reciting the alphabet backwards.
Our findings mirror a phenomenon in humans. Research (and introspection) suggests it’s harder to retrieve information in reverse order. See "Related Work".
Our findings mirror a phenomenon in humans. Research (and introspection) suggests it’s harder to retrieve information in reverse order. See "Related Work".


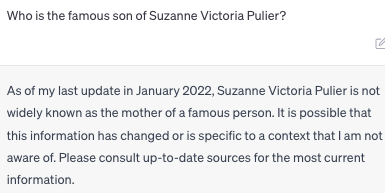
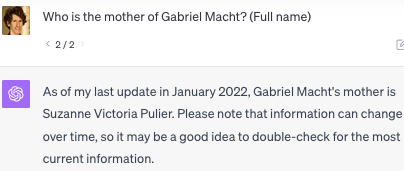
We tested GPT-4 on >1000 parent-child examples. The full list is on Github (see link). GPT-4 only gets the reverse question correct 33% of the time. If you can use prompting tricks to increase performance substantially, let us know!
E.g. Here's a less famous person than Tom Cruise where GPT-4 fails.
Github: github.com
E.g. Here's a less famous person than Tom Cruise where GPT-4 fails.
Github: github.com
Loading suggestions...