

The ML research ecosystem can be amazing. A few hours ago, I wondered: do pruned neural networks converge to high accuracies faster than the original networks? I'm sure I can find an answer in one of many lottery ticket hypothesis papers, but I wanted to explore myself. (1/5)
First, I thought about how to formulate the question as an experiment. I would need to train a small FC network on MNIST, prune, and retrain. I forked the original LTH paper repo, ran the experiment, and plotted the test set accuracies for epochs 1 to 15. (2/5)
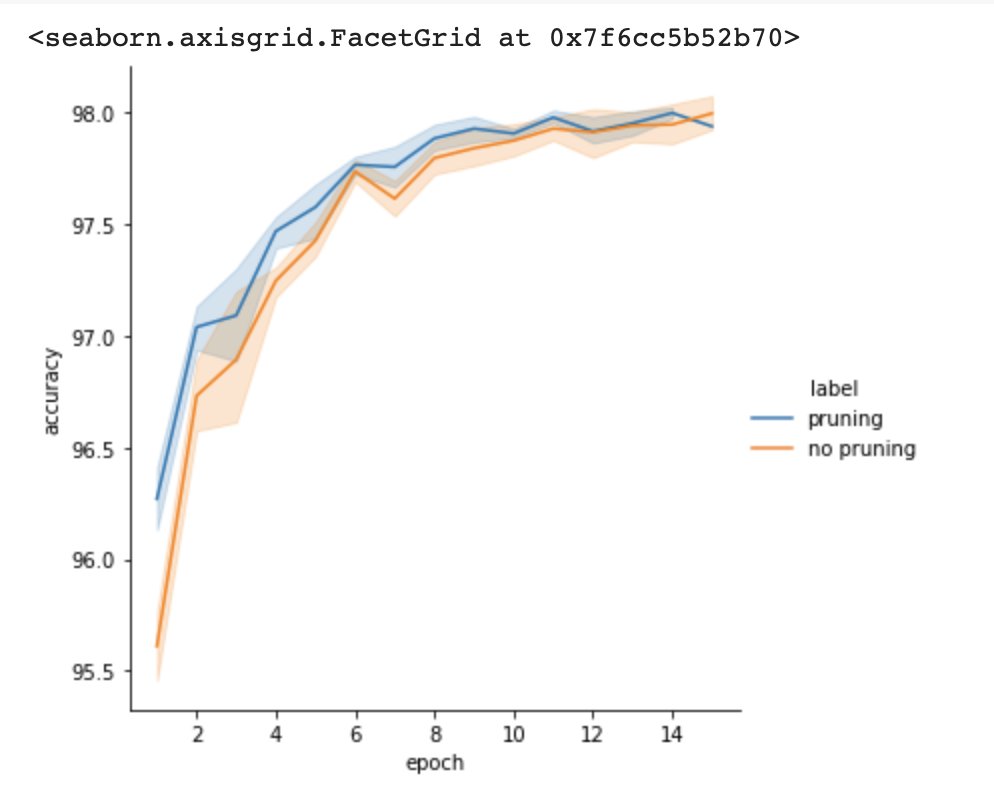
Then, I wondered, what would happen if I randomly dropped the same number of connections?
Looks like the pruned network with its original weight init converged quickest in the beginning! But this is only one expt on one model on one dataset; don't draw any conclusions. (3/5)
Looks like the pruned network with its original weight init converged quickest in the beginning! But this is only one expt on one model on one dataset; don't draw any conclusions. (3/5)
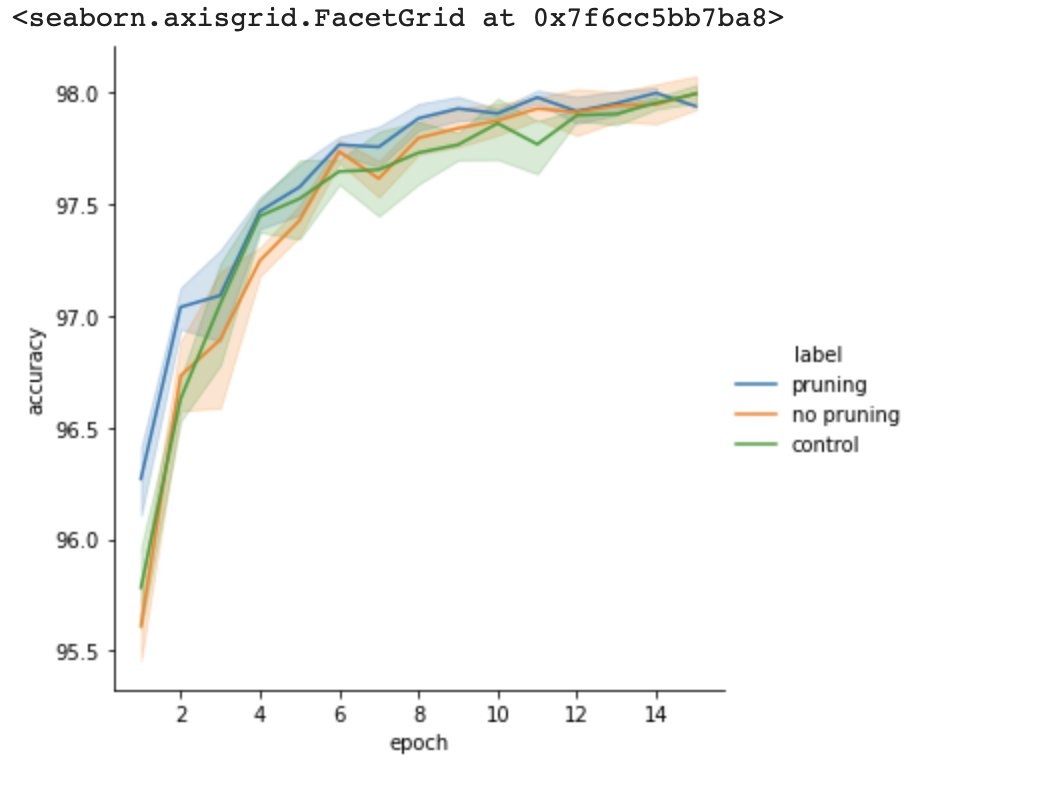
None of this is intended to be "true science" or "research" by any means, but I'm amazed that I was able to think of a question and find the resources to explore it. The codebase was so easy to use -- I literally only added a few lines of code: github.com (4/5)
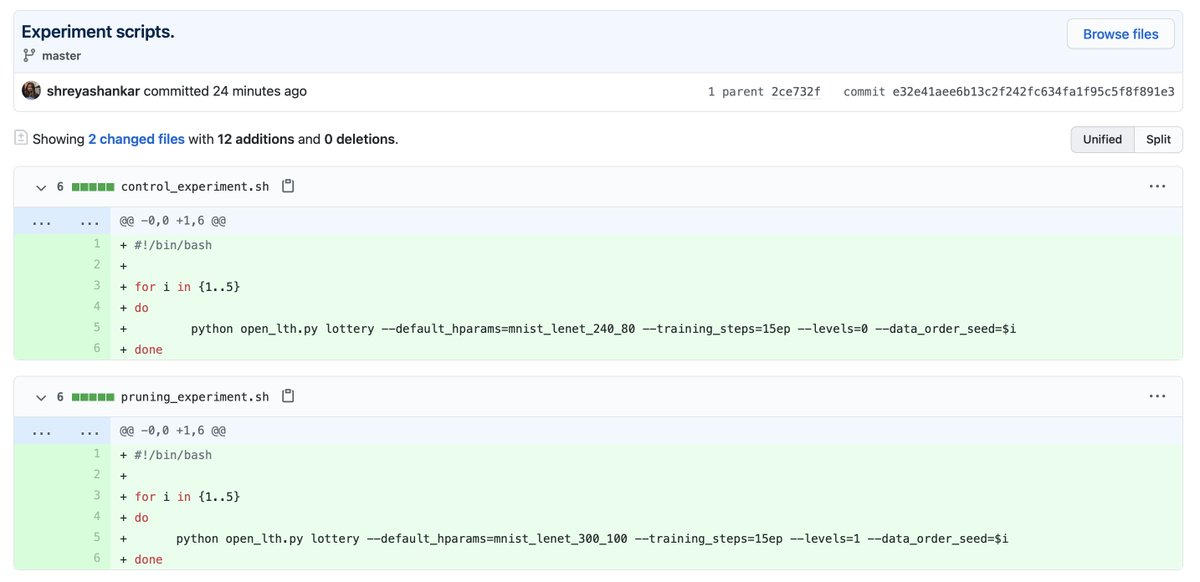
There's a lot of ML research crap out there, but it's important to highlight when ML research shines. This story is truly a testament to the infrastructure that some ML researchers painstakingly develop. I'm lucky to be in such a field, even if I'm not a researcher. (5/5)
Loading suggestions...