

Google spent $36,847 an hour for 40 days straight to train a machine learning model called AlphaGo.
Put simply, making these models is an expensive and lengthy process.
Here's how you can potentially train your models upto 2x faster with the magic of parallelization🧵
Put simply, making these models is an expensive and lengthy process.
Here's how you can potentially train your models upto 2x faster with the magic of parallelization🧵
Training a machine learning model is typically a 3 step process called 'ETL', which stands for:
- Extraction
- Transformation
- Loading
Let's take a closer look at these phases.
- Extraction
- Transformation
- Loading
Let's take a closer look at these phases.
1/ Extraction
This is start of the machine learning pipeline where the raw data is extracted from wherever it is stored.
This data needs to be processed before it is fed into the model.
This is start of the machine learning pipeline where the raw data is extracted from wherever it is stored.
This data needs to be processed before it is fed into the model.
2/ Transformation
During this phase the extracted data is transformed and manipulated according to our needs.
This can include things like data augmentation, resizing, normalization etc.
During this phase the extracted data is transformed and manipulated according to our needs.
This can include things like data augmentation, resizing, normalization etc.
3/ Loading
Now that we've extracted and transformed the data, it is ready to be fed to the model!
As the name suggests, during this phase the data is loaded for training on the neural network.
Now that we've extracted and transformed the data, it is ready to be fed to the model!
As the name suggests, during this phase the data is loaded for training on the neural network.

Essentially what happens here in this code is that:
A. The extraction and transformation steps take place on the CPU, which loads and transforms the data in batches.
B. Then that processed batch of data is loaded onto the GPU for training.
A. The extraction and transformation steps take place on the CPU, which loads and transforms the data in batches.
B. Then that processed batch of data is loaded onto the GPU for training.
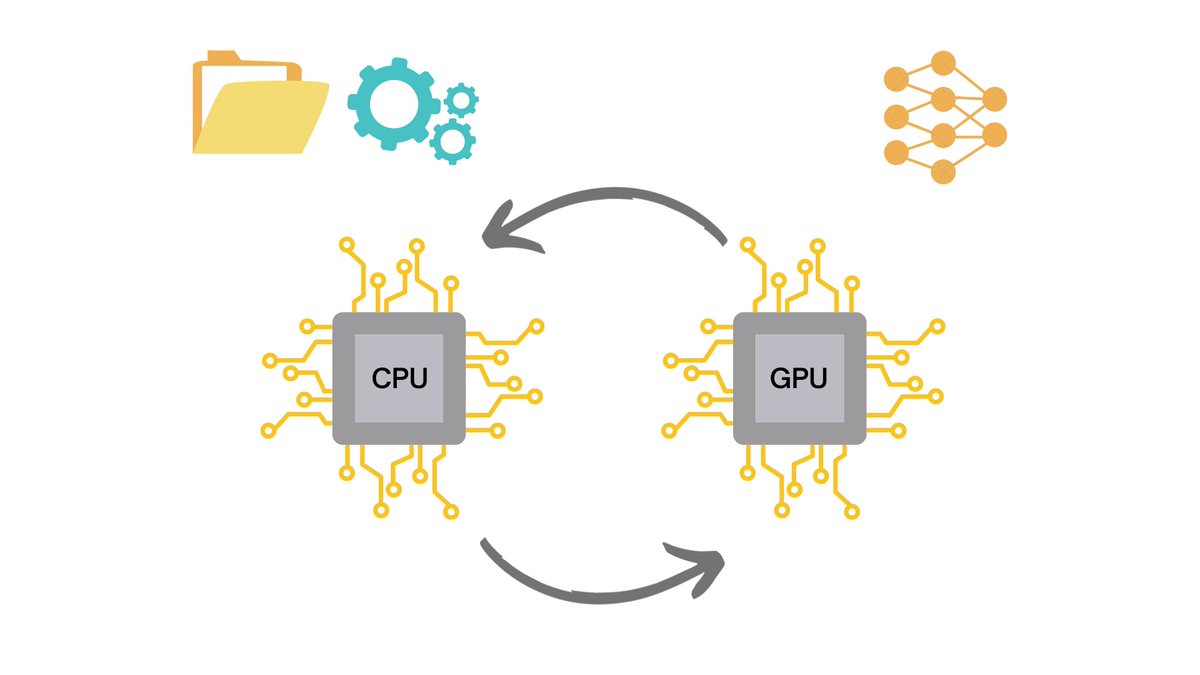
When training a machine learning model, we usually never load the entire data into the model because we have limited memory to work with.
The CPU prepares batches of data and then sends them to the GPU one by one to train the model.
The CPU prepares batches of data and then sends them to the GPU one by one to train the model.
The problem that arises here is that when the CPU is and transforming the data for a particular batch, the GPU is basically sitting there doing absolutely nothing.
Vice versa, the CPU is idle when the GPU is training.
As we can see this is clearly inefficient.
Vice versa, the CPU is idle when the GPU is training.
As we can see this is clearly inefficient.
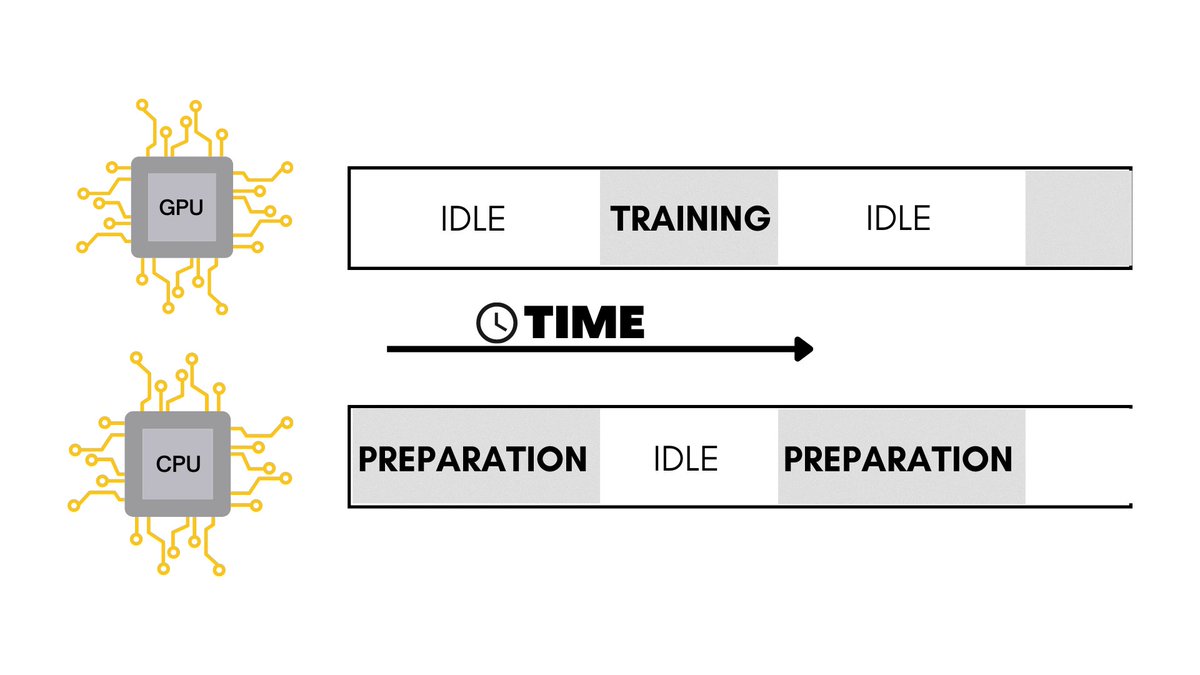
What if there was a way to make the CPU prepare the next batch of data while the GPU trains on the current one?
Say hello to ETL parallelization! 👋
Say hello to ETL parallelization! 👋
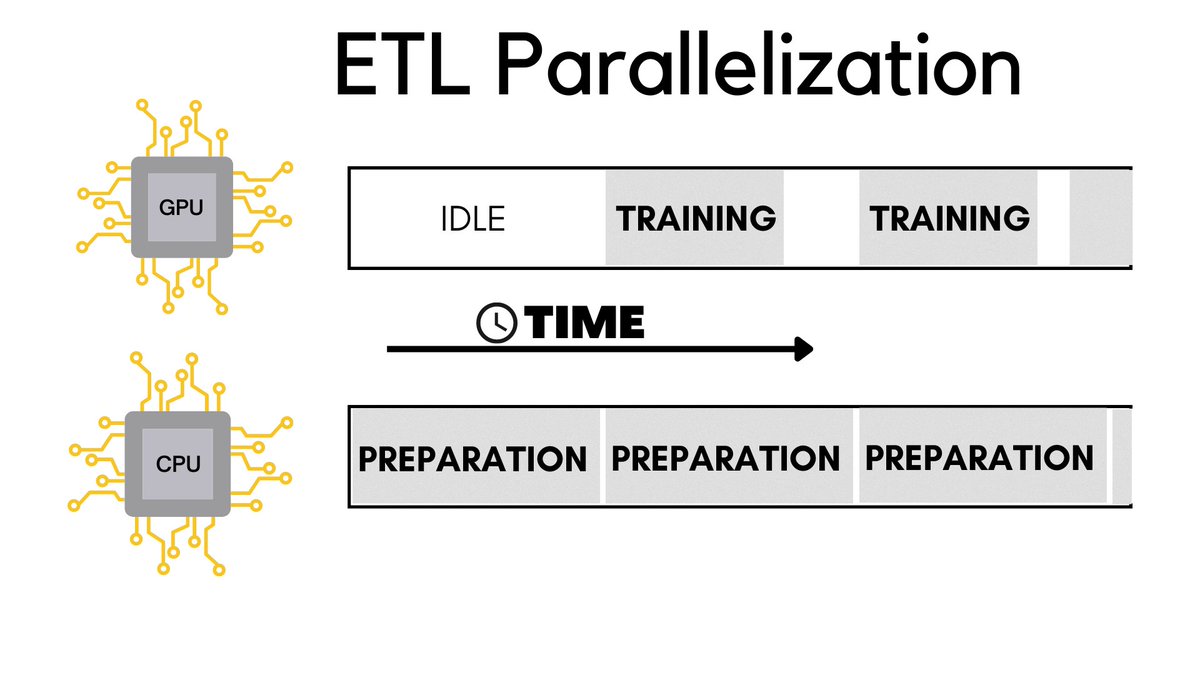
The idea here is that while the GPU gets trained on a batch of data, the CPU can simultaneously prepare the next batch to be fed in.
It is only for the very first iteration that the GPU has to be idle waiting for the CPU to extract and load the data.
It is only for the very first iteration that the GPU has to be idle waiting for the CPU to extract and load the data.
Here's the same model that I showed you before, but this time I've tweaked it to paralellize the ETL phases.
Take your time and feel free to read through the entire thing.
gist.github.com
Take your time and feel free to read through the entire thing.
gist.github.com

Running both these models for 15 epochs on my M1 Macbook pro took about 6 minutes on the regular model and 3 minutes on ETL optimised variant.
We've roughly halved the training time, sweet!
We've roughly halved the training time, sweet!
If you enjoyed this thread and found it useful, make sure you retweet it.
Follow @PrasoonPratham and you might learn a thing or two about machine learning, see you next time!
Follow @PrasoonPratham and you might learn a thing or two about machine learning, see you next time!
You can also read this post on my blog👇
prathamprasoon.com
prathamprasoon.com
Loading suggestions...