

One of my fave chapters of "Practical Deep Learning for Coders", co-written with @GuggerSylvain, is chapter 8. I've just made the whole thing available as an executable notebook on Kaggle!
It covers a lot of critical @PyTorch & deep learning principles 🧵
kaggle.com
It covers a lot of critical @PyTorch & deep learning principles 🧵
kaggle.com
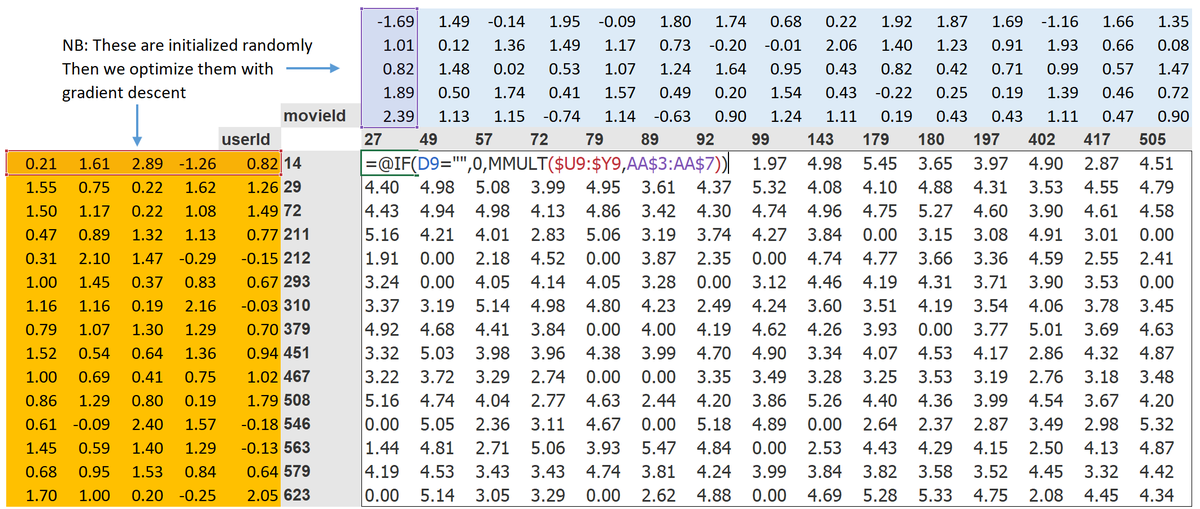
The chapter looks at the "matrix completion" problem at the heart of recommendation systems -- e.g what would you guess are the missing values in this matrix showing what rating users gave movies?

The key idea is to find the "latent factors" behind people's preferences

If we knew the latent factors for each user and each movie, we could calculate their predicted rating in a spreadsheet using dot product like this:
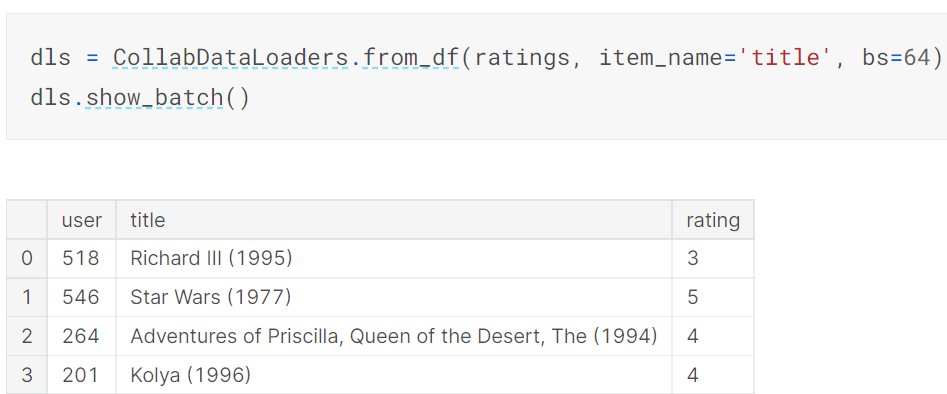
We can calculate those latent factors using stochastic gradient descent. We can construct the data loaders we need using the appropriate @fastdotai application
To manually create a model to do what Excel is doing, we need some way to handle the high cardinality categorical inputs (movie and user IDs). It turns out that we can just do an array index lookup, which is actually identical to multiplying by a 1-hot encoded vector
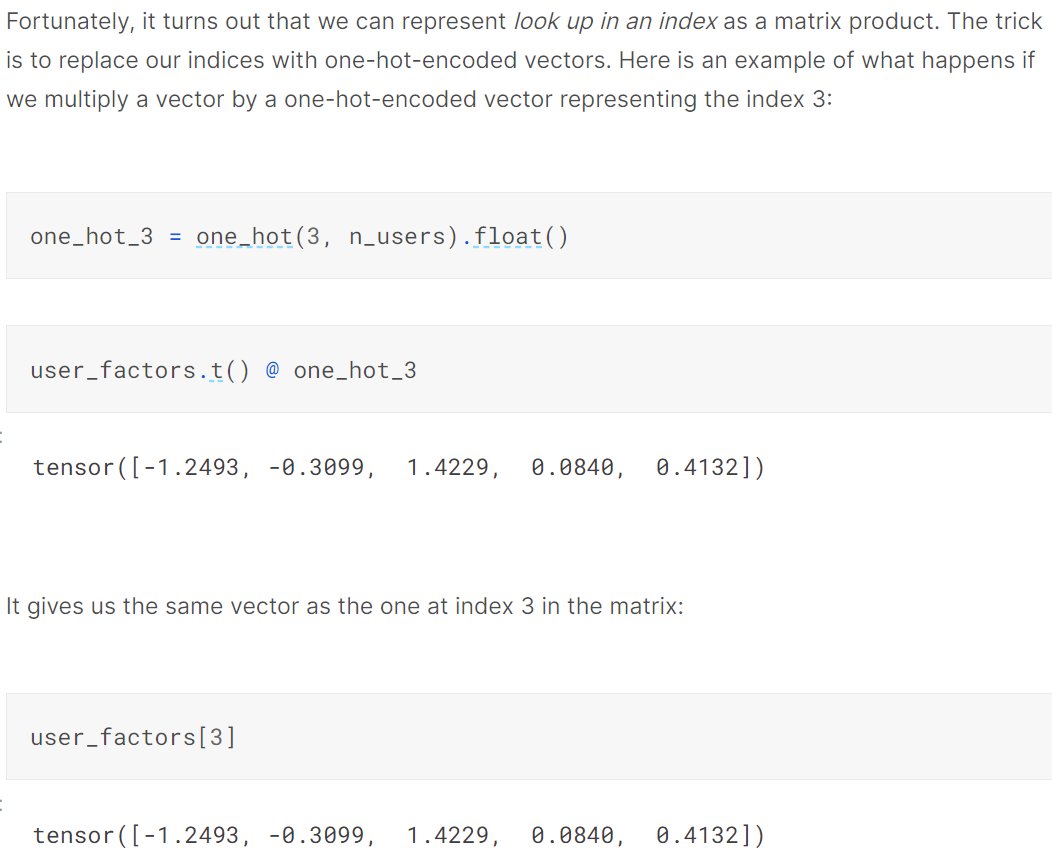
This trick of doing an array index lookup, which is identical to multiplying by a 1-hot encoded vector, is known as an "Embedding".
We can create a complete collaborative filtering model in @PyTorch from scratch using this trick:
We can create a complete collaborative filtering model in @PyTorch from scratch using this trick:

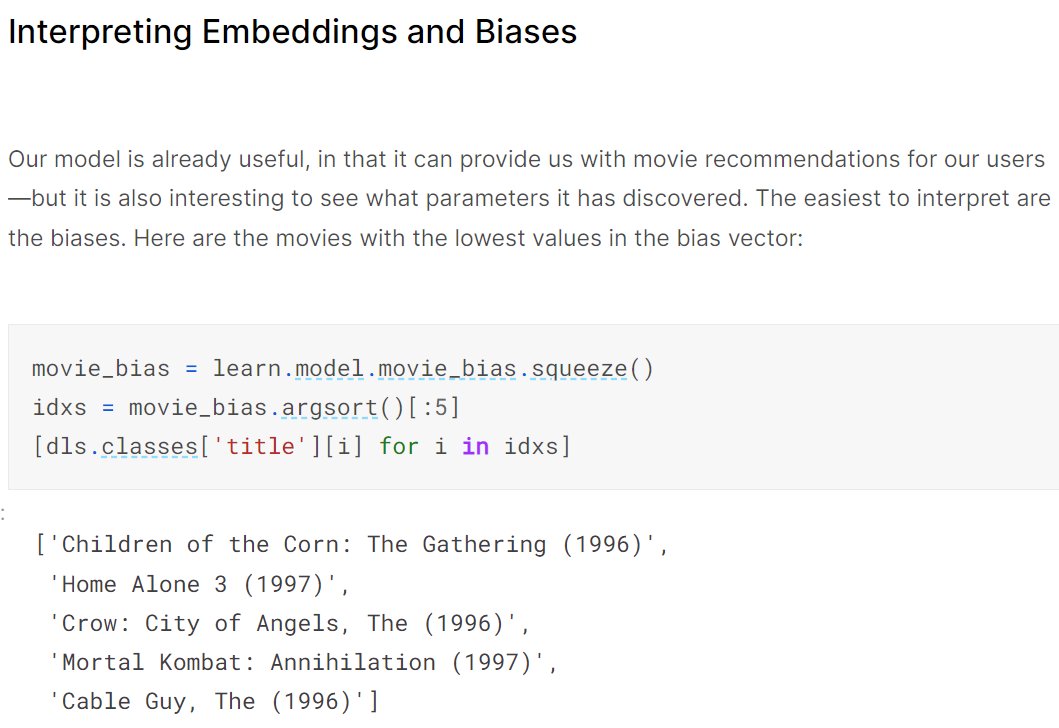
We can use these trained parameters to interpret the model - for instance, here are the world's most disappointing movies, according to this data:
We can also interpret the actual embedding matrices, by first extracting the principal components with PCA. Here's how some of the movies in our data are clustered based on this approach:
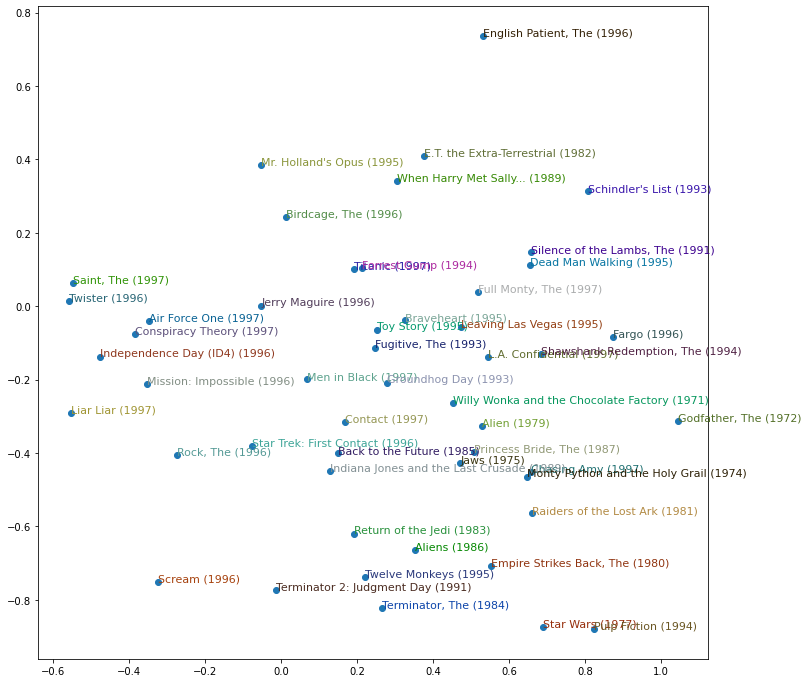
We can also use the model to do a similarity search:

Of course, you don't have to create your model from scratch - here's how to do it in 2 lines of code with fastai:
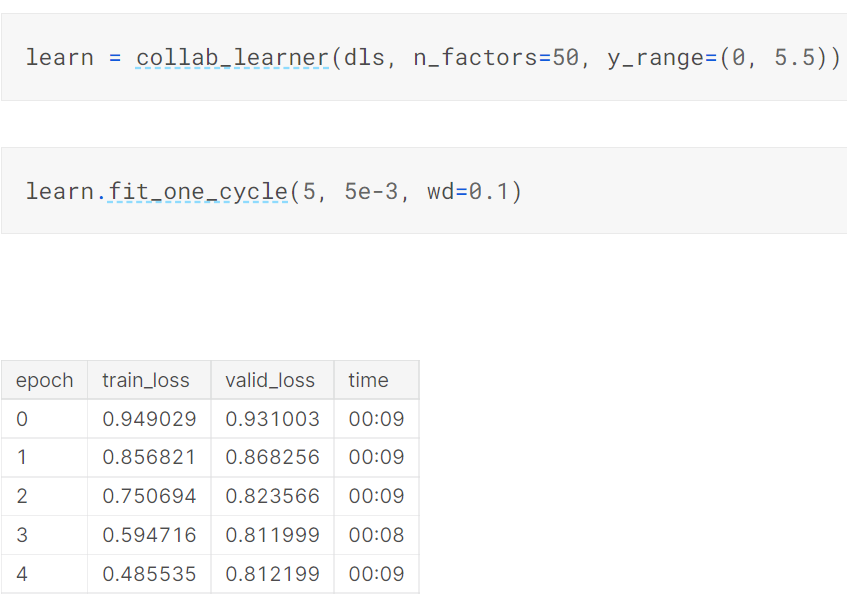
There's lots more covered in the full chapter, so please do check it out -- and be sure to try executing it yourself so you can do your own experiments:
kaggle.com
kaggle.com
If you'd like to order a copy of the book yourself, here it is:
amazon.com
amazon.com
Chapter 1 of the book is also available on @kaggle.
(Oh and BTW, if you like my notebooks, please upvote them on Kaggle, because it helps others find them, and motivates me to do more because I know they're appreciated!)
kaggle.com
(Oh and BTW, if you like my notebooks, please upvote them on Kaggle, because it helps others find them, and motivates me to do more because I know they're appreciated!)
kaggle.com
Loading suggestions...