

There is one big reason we love the logarithm function in machine learning.
Logarithms help us reduce complexity by turning multiplication into addition. You might not know it, but they are behind a lot of things in machine learning.
↓ Here is the entire story. ↓
Logarithms help us reduce complexity by turning multiplication into addition. You might not know it, but they are behind a lot of things in machine learning.
↓ Here is the entire story. ↓

First, let's start with the definition of the logarithm.
The base 𝑎 logarithm of 𝑏 is simply the solution of the equation 𝑎ˣ = 𝑏.
Despite its simplicity, it has many useful properties that we take advantage of all the time.
The base 𝑎 logarithm of 𝑏 is simply the solution of the equation 𝑎ˣ = 𝑏.
Despite its simplicity, it has many useful properties that we take advantage of all the time.
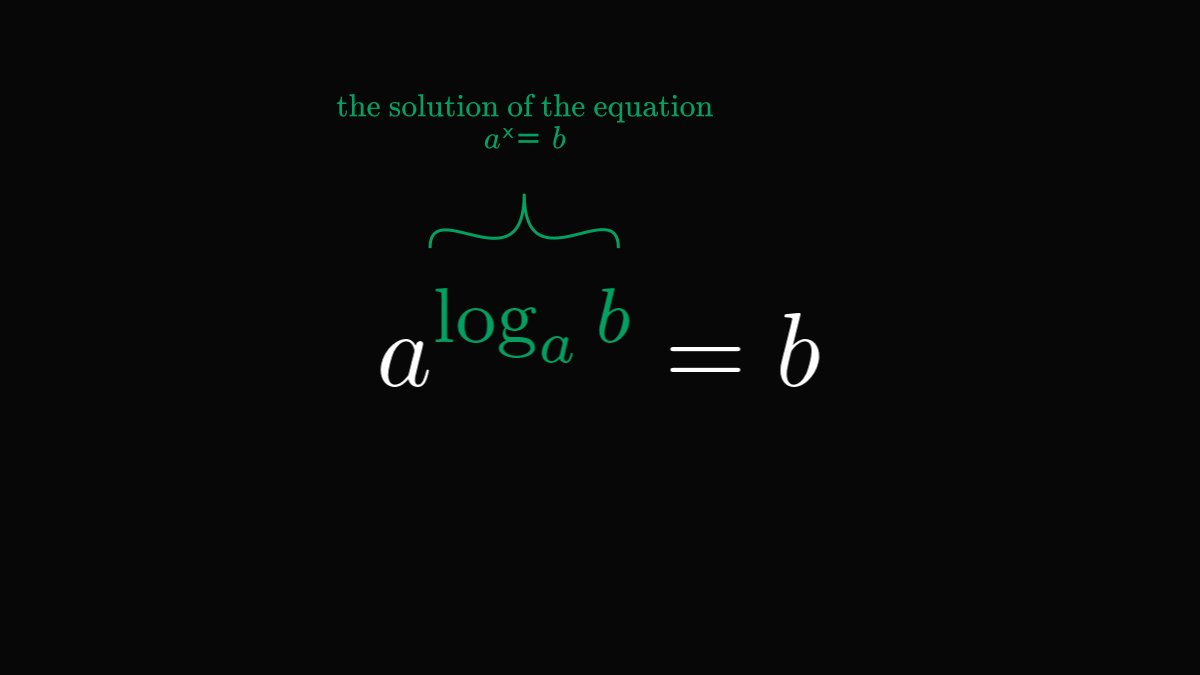
You can think of the logarithm as the inverse of exponentiation.
Because of this, it turns multiplication into addition. Exponentiation does the opposite: it turns addition into multiplication.
(The base is often assumed to be a fixed constant. Thus, it can be omitted.)
Because of this, it turns multiplication into addition. Exponentiation does the opposite: it turns addition into multiplication.
(The base is often assumed to be a fixed constant. Thus, it can be omitted.)

Why is this useful? Because we can use it to calculate gradients and derivatives!
Training a neural network requires finding its gradient. However, lots of commonly used functions are written in terms of products.
As you can see, this complicates things.
Training a neural network requires finding its gradient. However, lots of commonly used functions are written in terms of products.
As you can see, this complicates things.

By taking the logarithm, we can easily compute the derivative as it turns products into sums.
This method is called logarithmic differentiation.
This method is called logarithmic differentiation.
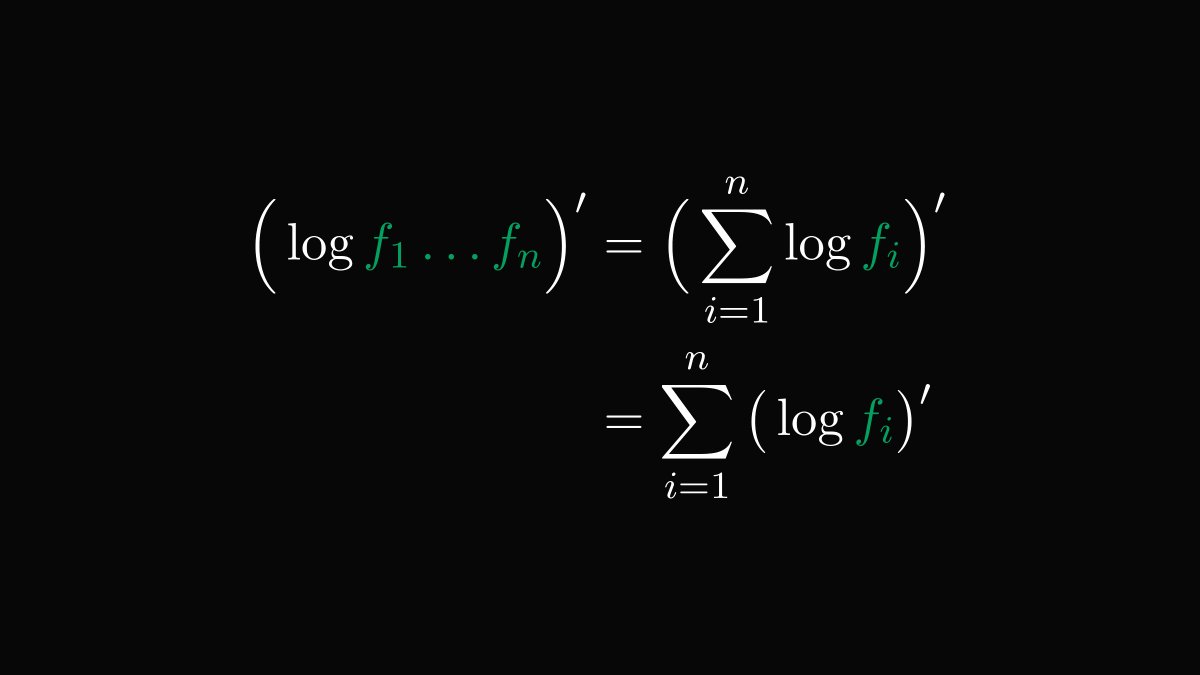
One example where this is useful is the maximum likelihood estimation.
Given a set of observations and a predictive model, we can write this in the following form.
Given a set of observations and a predictive model, we can write this in the following form.

Believe it or not, this is behind the mean squared error.
Every time you use this, logarithms are working in the background.
Every time you use this, logarithms are working in the background.

Having a deep understanding of math will make you a better engineer. I want to help you with this, so I am writing a comprehensive book about the subject.
If you are interested in the Mathematics of Machine Learning, check out the early access!
tivadardanka.com
If you are interested in the Mathematics of Machine Learning, check out the early access!
tivadardanka.com
You can read the unrolled thread here: tivadardanka.com
Loading suggestions...