

AI image generation is the most recent mind-blowing AI capability.
#StableDiffusion is a clear milestone in this development because it made a high-performance model available to the masses.
This is how it works.
1/n
#StableDiffusion is a clear milestone in this development because it made a high-performance model available to the masses.
This is how it works.
1/n

It is versatile in that it can be used in a number of different ways.
Text => Image (like the image above) is the main use case.
Another one is (Image + Text) => Image (Like this image). This is called img2img.
2/n
Text => Image (like the image above) is the main use case.
Another one is (Image + Text) => Image (Like this image). This is called img2img.
2/n

Stable Diffusion is a system made up of several components and models. It is not one monolithic model.
As we look under the hood, the first distinction we can make is that there’s:
1- A text understanding component
2- An image generation component
3/n
As we look under the hood, the first distinction we can make is that there’s:
1- A text understanding component
2- An image generation component
3/n


The image generator goes through two steps:
1- Image information creation - the secret sauce of stable diffusion. Runs for a number of steps refining the information that should go in the image
2- Image decoder, takes the processed information and paints the picture
5/n
1- Image information creation - the secret sauce of stable diffusion. Runs for a number of steps refining the information that should go in the image
2- Image decoder, takes the processed information and paints the picture
5/n
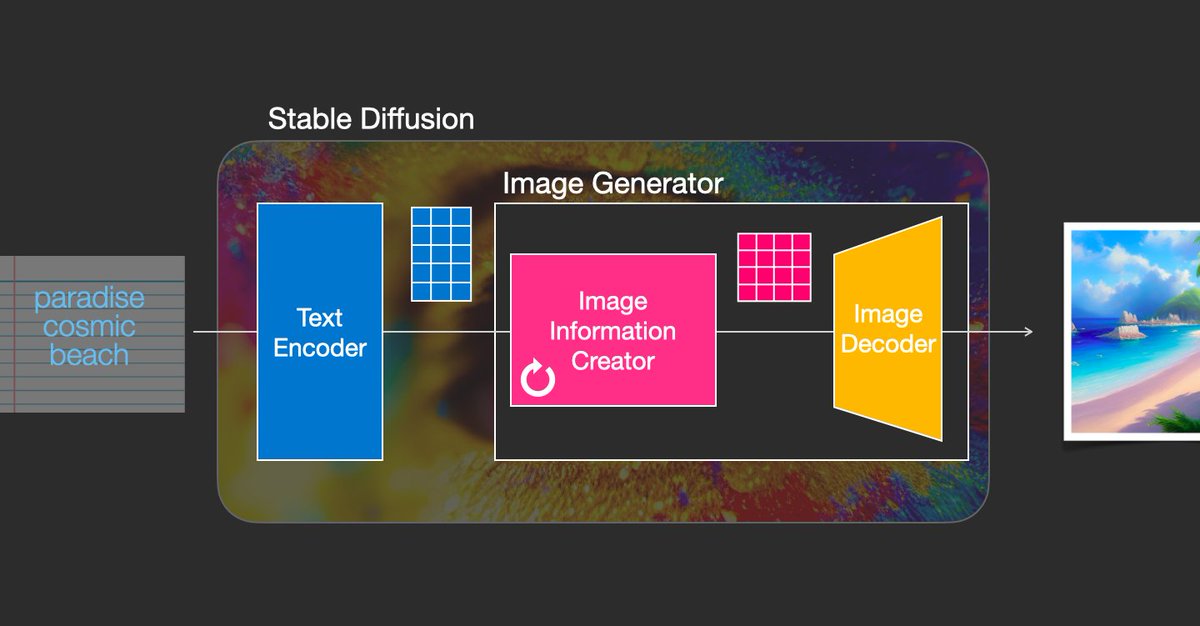
This brings us to the 3 central components of the image creation process. Separate neural networks working together:
- CLIPText: for text encoding
- U-Net + scheduler: to gradually process image information (latent diffusion)
- Autoencoder Decoder: paints the final image
6/n
- CLIPText: for text encoding
- U-Net + scheduler: to gradually process image information (latent diffusion)
- Autoencoder Decoder: paints the final image
6/n

What is diffusion?
It's the process of transforming a random collection of numbers (the "latents tensor") into a processed collection of numbers containing the right image information.
It's a step-by-step process (the "# Steps" parameter in stable diffusion).
7/n
It's the process of transforming a random collection of numbers (the "latents tensor") into a processed collection of numbers containing the right image information.
It's a step-by-step process (the "# Steps" parameter in stable diffusion).
7/n

We can actually visualize the process by using the same image decoder.
The starting random vector is painted as random noise.
Stable Diffusion's speed boost comes from the fact that this processing happens in the latent space (less calculations than pixel space).
8/n
The starting random vector is painted as random noise.
Stable Diffusion's speed boost comes from the fact that this processing happens in the latent space (less calculations than pixel space).
8/n
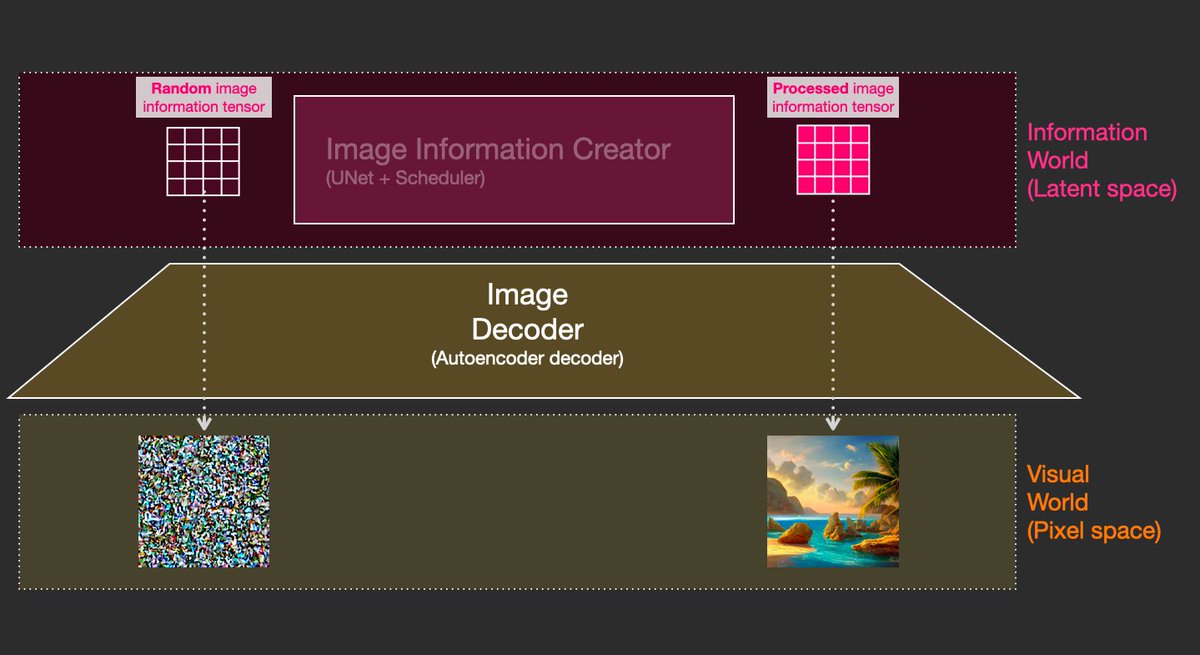
Each step in the process applies a neural network (U-Net) on the previous output (starting with the random tensor).
Each step removes noise and adds more visual detail. It is also informed by the text (the cfg parameter determines by how much).
9/n
Each step removes noise and adds more visual detail. It is also informed by the text (the cfg parameter determines by how much).
9/n

Loading suggestions...