

Stateful Active Facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning
@DianboLiu, @b0ussifo, @Cmeo97, @anirudhg9119, Tianmin Shu, Michael Mozer, Nicolas Heess & Yoshua Bengio
@Mila_Quebec
arxiv.org
(1/N)
@DianboLiu, @b0ussifo, @Cmeo97, @anirudhg9119, Tianmin Shu, Michael Mozer, Nicolas Heess & Yoshua Bengio
@Mila_Quebec
arxiv.org
(1/N)
Reinforcement Learning in cooperative multi-agent settings requires individual agents to learn to work together in order to achieve a common goal. To attain optimal behavior, these agents need to learn to "coordinate" efficiently among each other.
(2/N)
(2/N)
However, MARL is faced with the unique challenge of changing environment dynamics as different agents update their policy parameters. This makes it difficult for the agents to learn efficiently coordinated behavior.
(3/N)
(3/N)
Further, in order to be robust, MARL in real world also needs to tackle "spatial" heterogeneity within the environment, i.e., changing structure, distribution of obstacles, transition dynamics, etc. A given MARL environment can be considered as having a certain level of
(4/N)
(4/N)
"heterogeneity" and requiring a certain level of "coordination" among the agents in order to solve it. However, there doesn't exist any suite of Reinforcement Learning environments that facilitates an empirical study of the effect of these parameters on MARL approaches and
(5/N)
(5/N)
on the difficulty of the task. To address this, we propose "HECOGrid" - a suite of environments containing three different procedurally generated tasks, each of which facilitates quantitative manipulation of the coordination and heterogeneity levels of the environment.
(6/N)
(6/N)
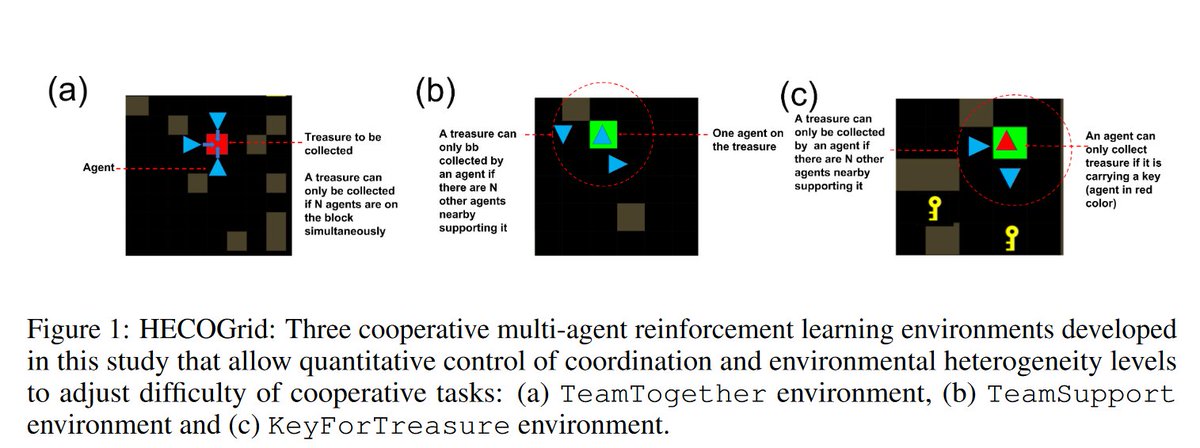
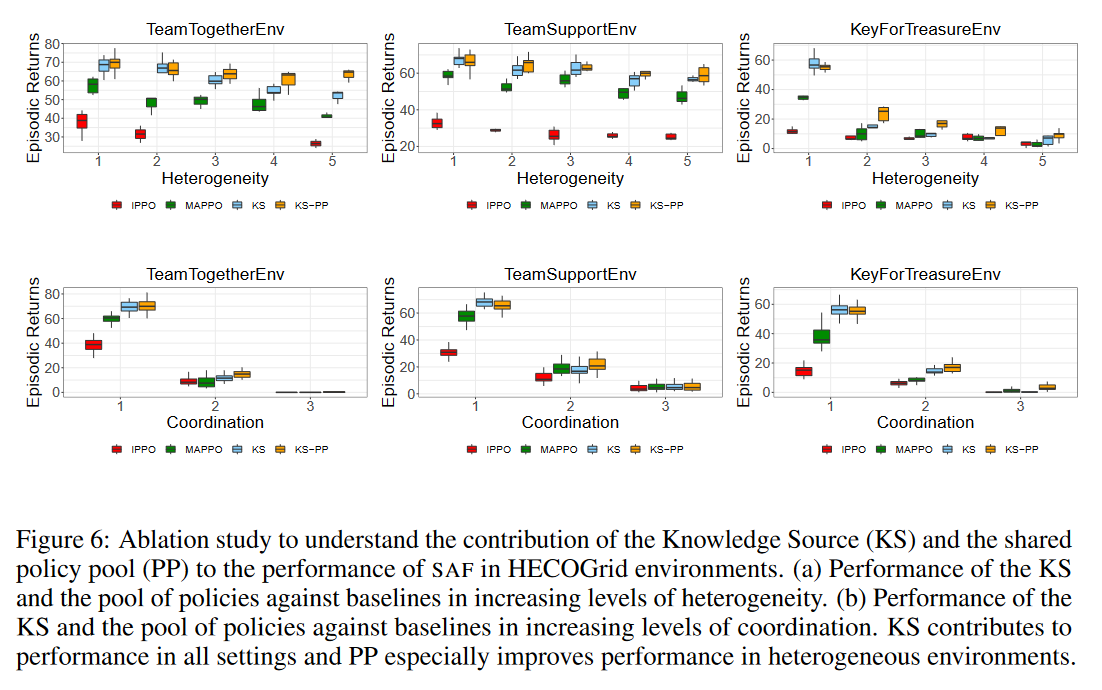
Further, we propose "Stateful Active Facilitator (SAF)", a new Centralized Training Decentralized Execution (CTDE) approach, consisting of a shared "Knowledge Source (KS)" and a "Pool of Policies (PP)". The KS bottlenecks information from all the agents..
(7/N)
(7/N)
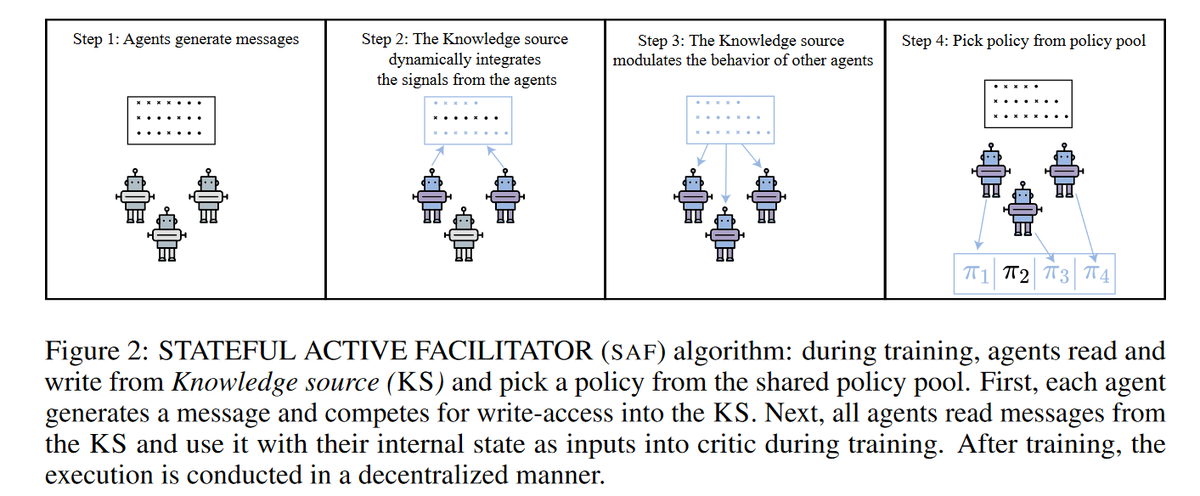
and each agent dynamically selects a policy from the PP for each step.
We compare the performance of SAF on HECOGrid tasks against that of MAPPO and IPPO. SAF outperforms both across different heterogeneity and coordination levels.
(8/N)
We compare the performance of SAF on HECOGrid tasks against that of MAPPO and IPPO. SAF outperforms both across different heterogeneity and coordination levels.
(8/N)
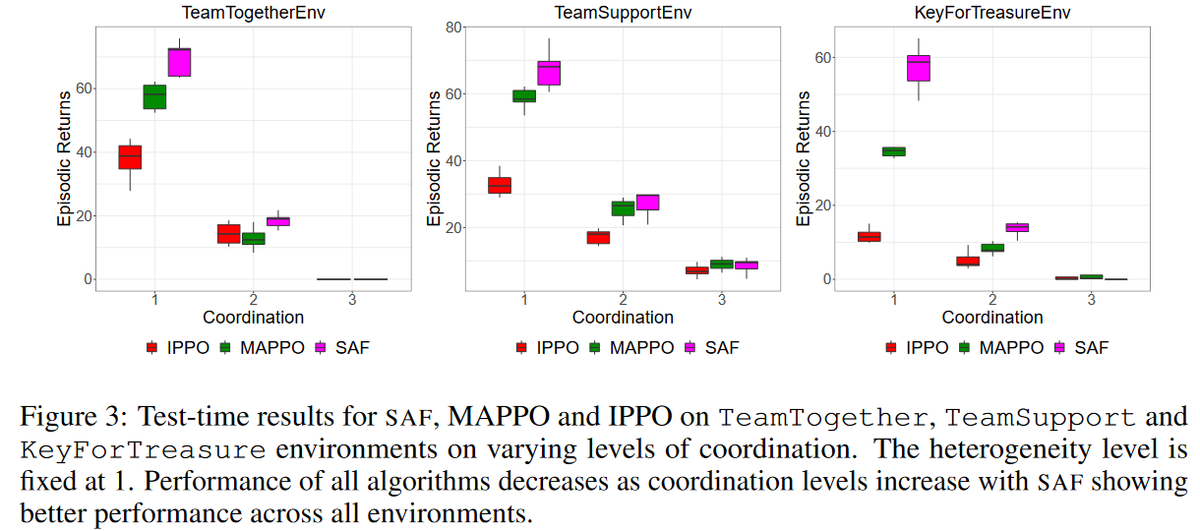
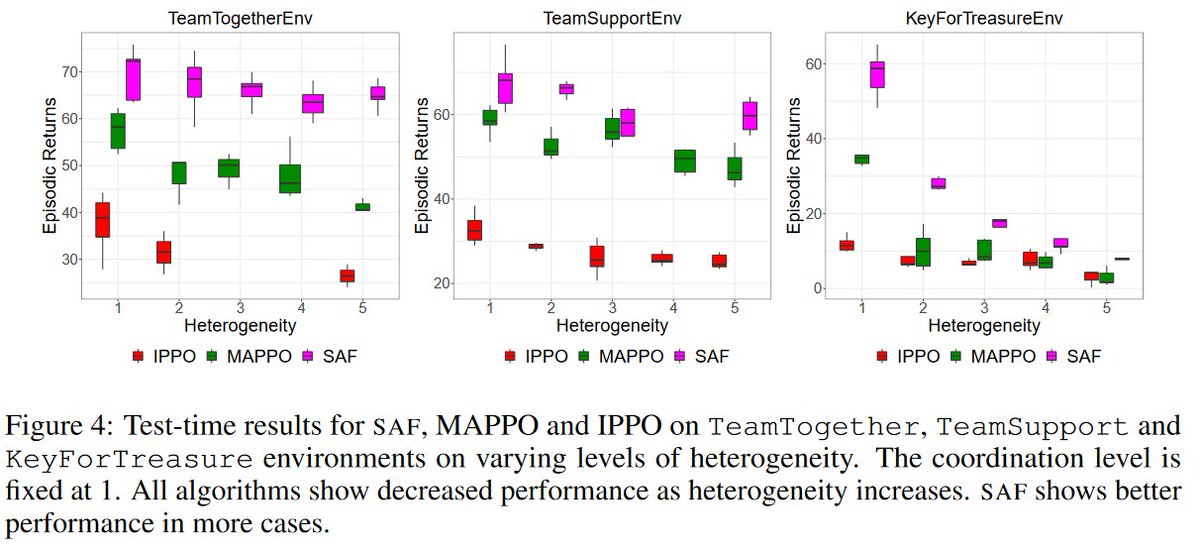
Ablation studies show that KS is the key to good performance across different coordination levels, whereas the pool of policies enables good performance across different heterogeneity levels.
(9/N)
(9/N)
Code used for conducting the experiments is available at:
github.com
We'll be releasing HECOGrid separately soon!
github.com
We'll be releasing HECOGrid separately soon!
Loading suggestions...