

Algumas novidades na análise utilizando inteligência artificial.
Primeiro, um dos erros básicos em Machine Learning é usar features com 0s. Então ajustei para rodar com valores baixos, substituindo os 0s por 0,001
Siga o fio 🧵🧵🧵
Primeiro, um dos erros básicos em Machine Learning é usar features com 0s. Então ajustei para rodar com valores baixos, substituindo os 0s por 0,001
Siga o fio 🧵🧵🧵

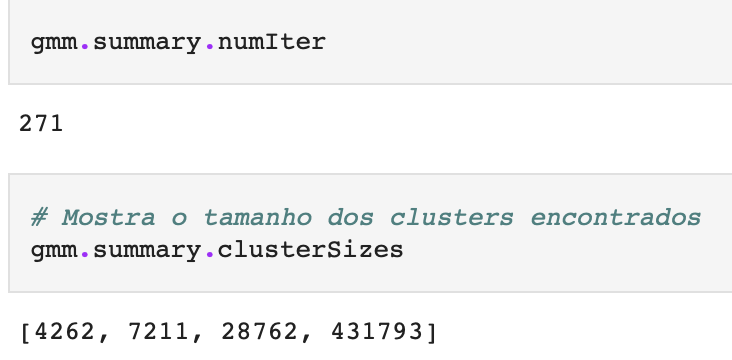
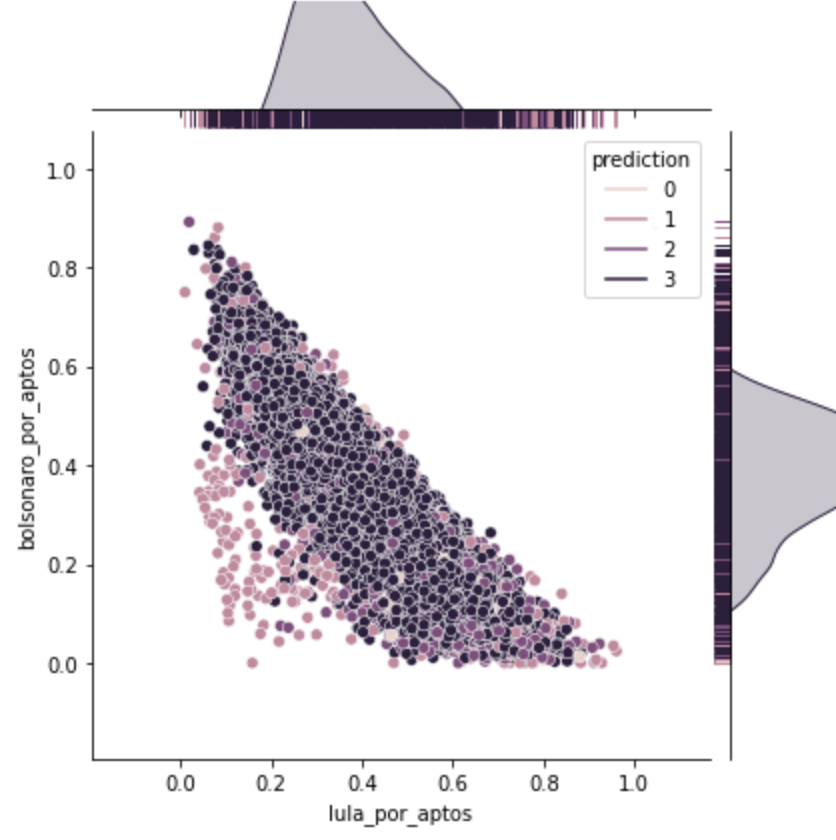
Com isso a análise ficou ainda mais consistente. Dividi tudo em 4 grupos, como antes. E ficou interessante. 3 grupos (0, 1, 2) com um total de umas 40 mil urnas e um grupo grande (3) com 430 mil urnas.

QuaOutro problema que tinha antes é que o algoritmo não estava encontrando a convergência com o padrão de apenas 100 iterações. Aumentei para 1000, mas ele encontrou o resultado com 271 iterações.
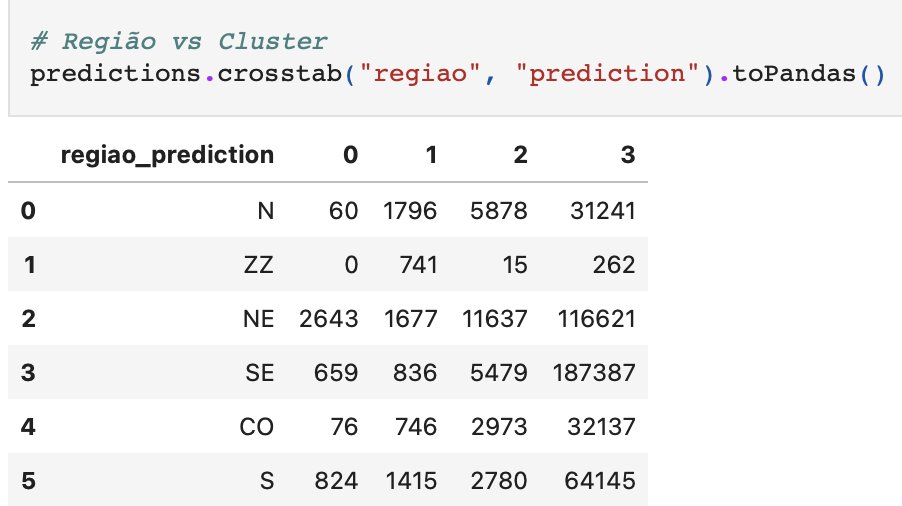
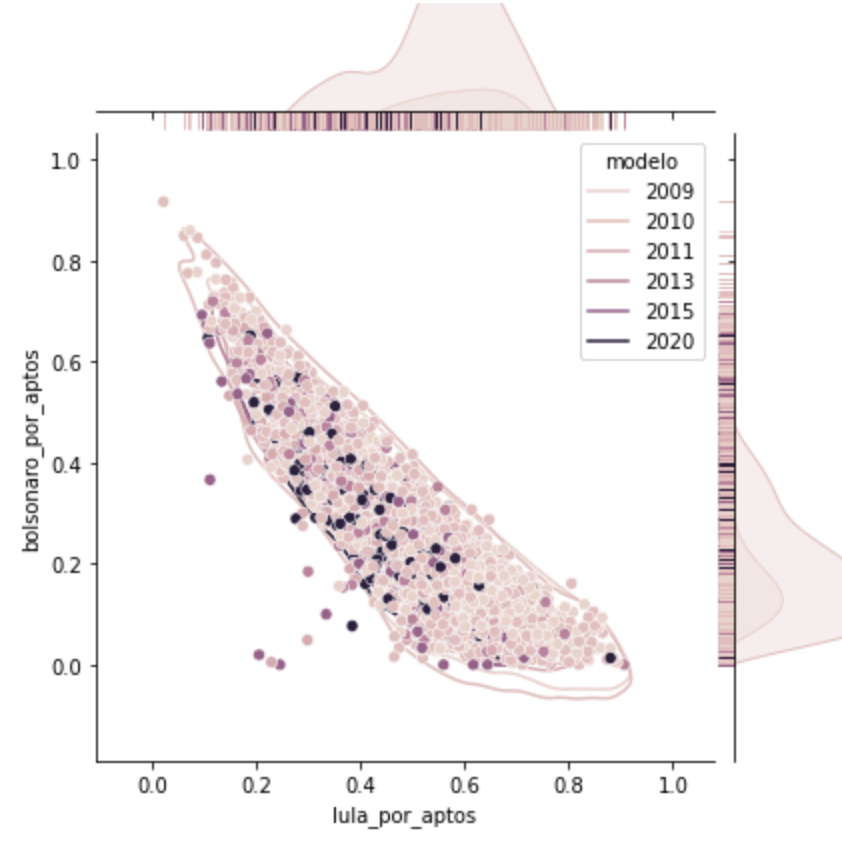
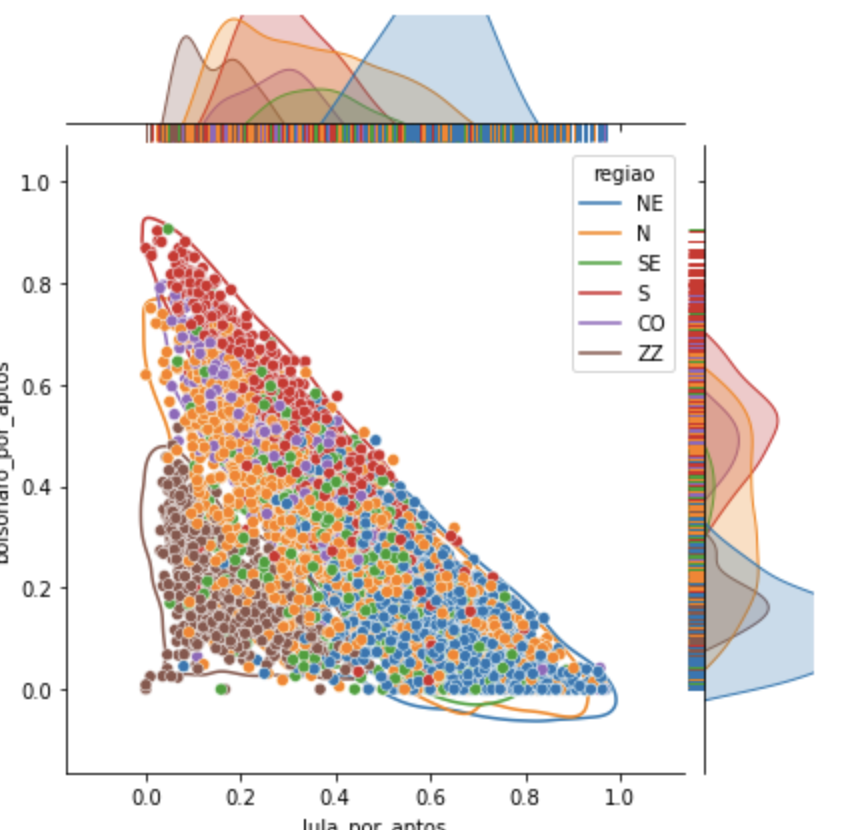
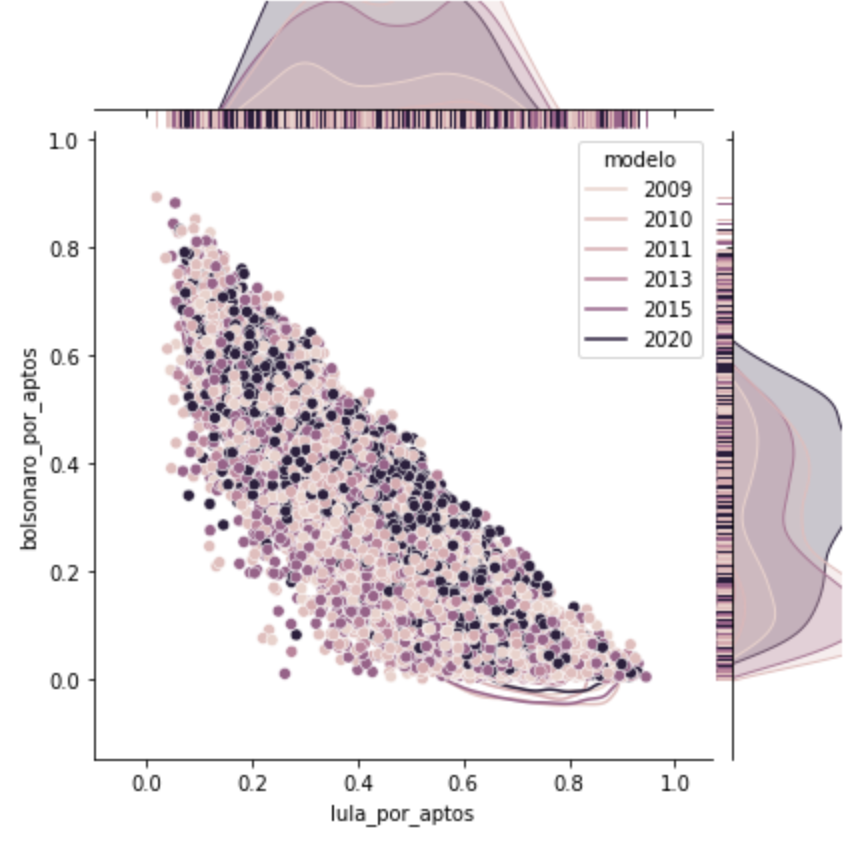
Quanto à região, há dominância no Nordeste em relação ao Sudeste nos grupos 0, 1 e 2. Quanto aos modelos de urnas, há proporcionalmente mais urnas antigas do que na média geral. No grupo 3, já fica mais próximo da média geral. (60% antiga, 40% nova)
app.powerbi.com
app.powerbi.com
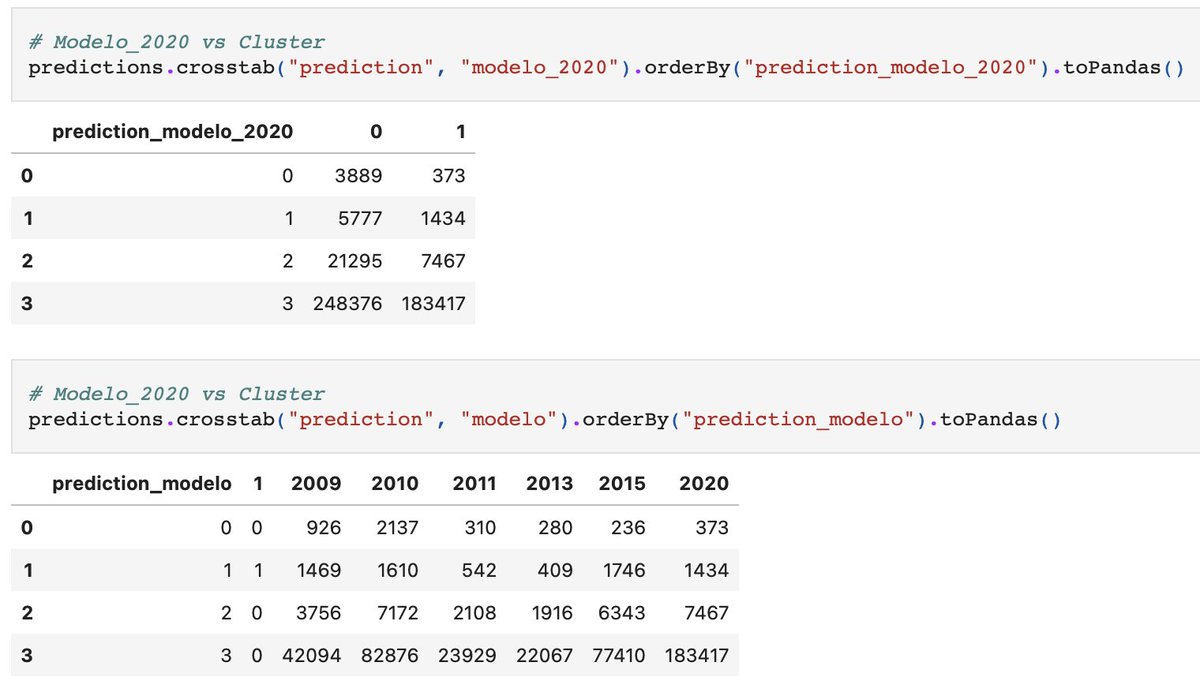
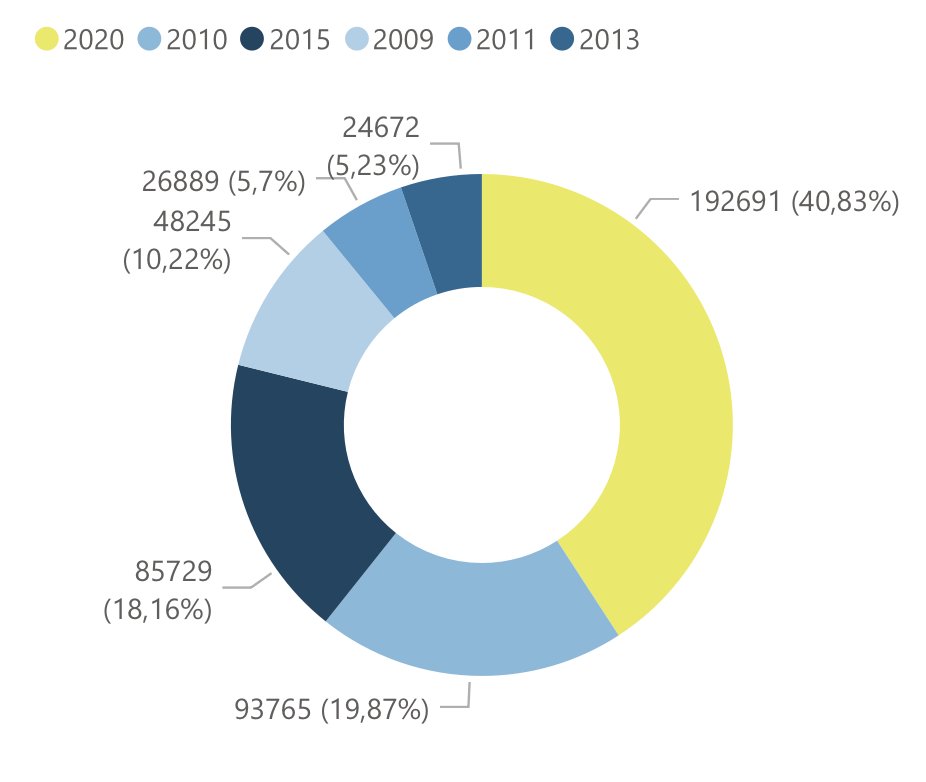
Quanto à distribuição dos grupos, agora o gráficou ficou assim, com maior dominância no grupo 3, os demais grupos aparecem nos cantos mais anômalos do gráfico.
Analisando o grupo 0 por modelo, podemos ver, nos gráficos de frequÊncia, uma distribuição ligeiramente "bimodal".
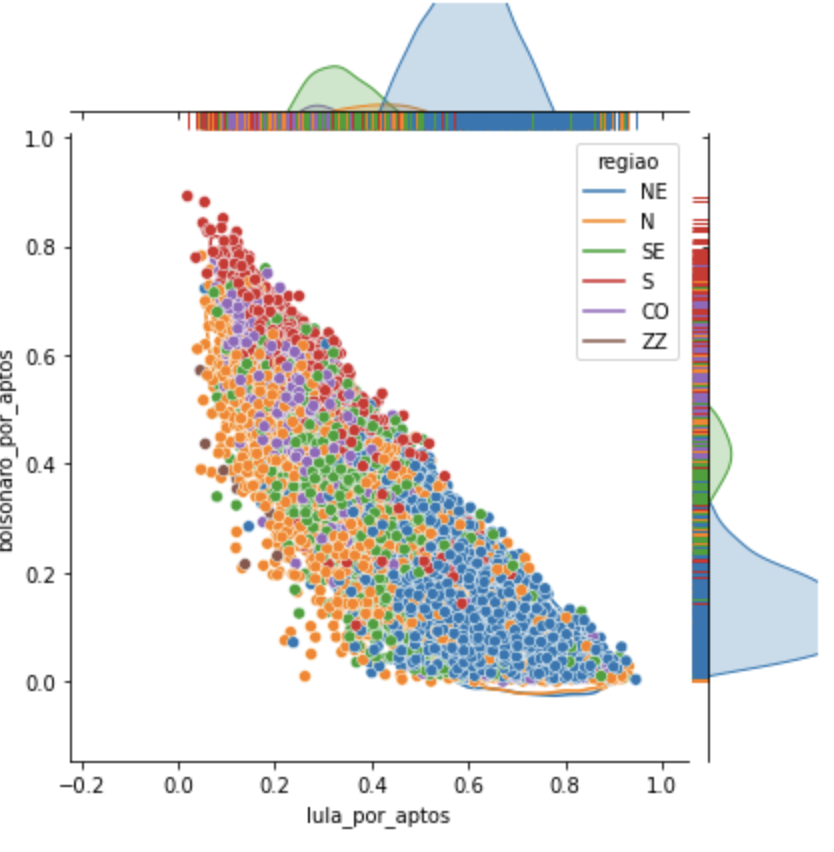
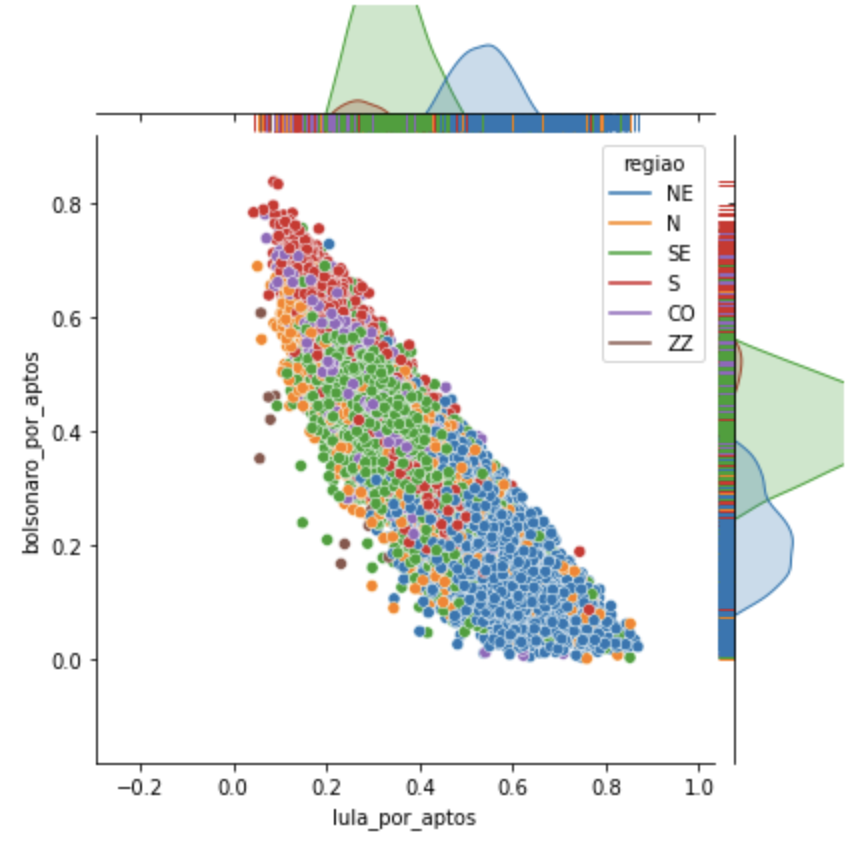
Olhando para o gráfico de região, notamos que a maior frequência se encontra no Nordeste, tornando as demais insignificantes para sequer aparecer no gráfico desse grupo.

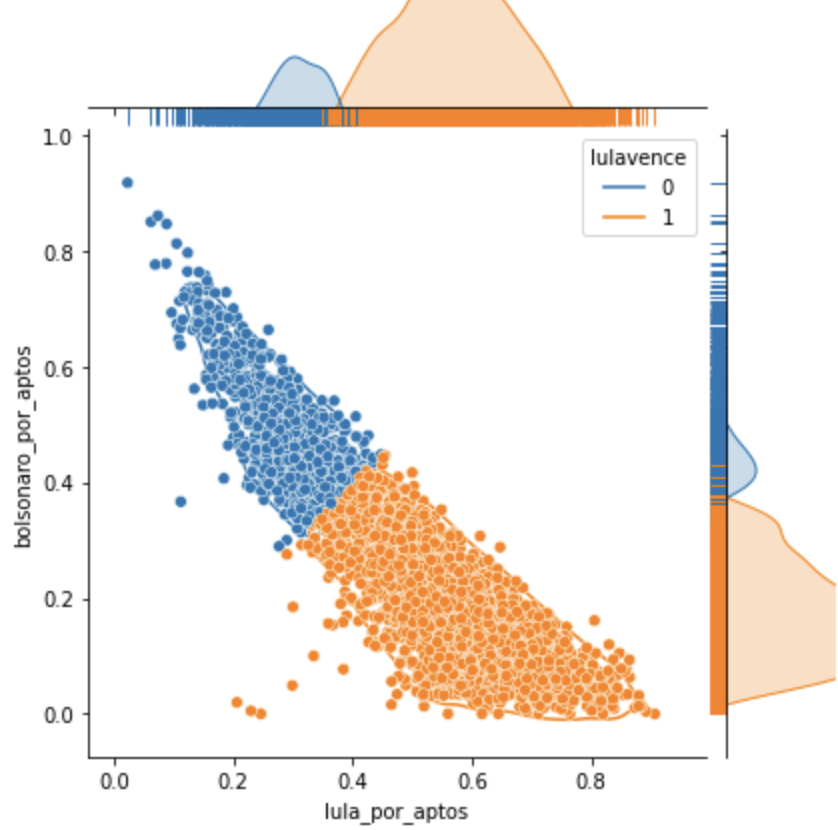
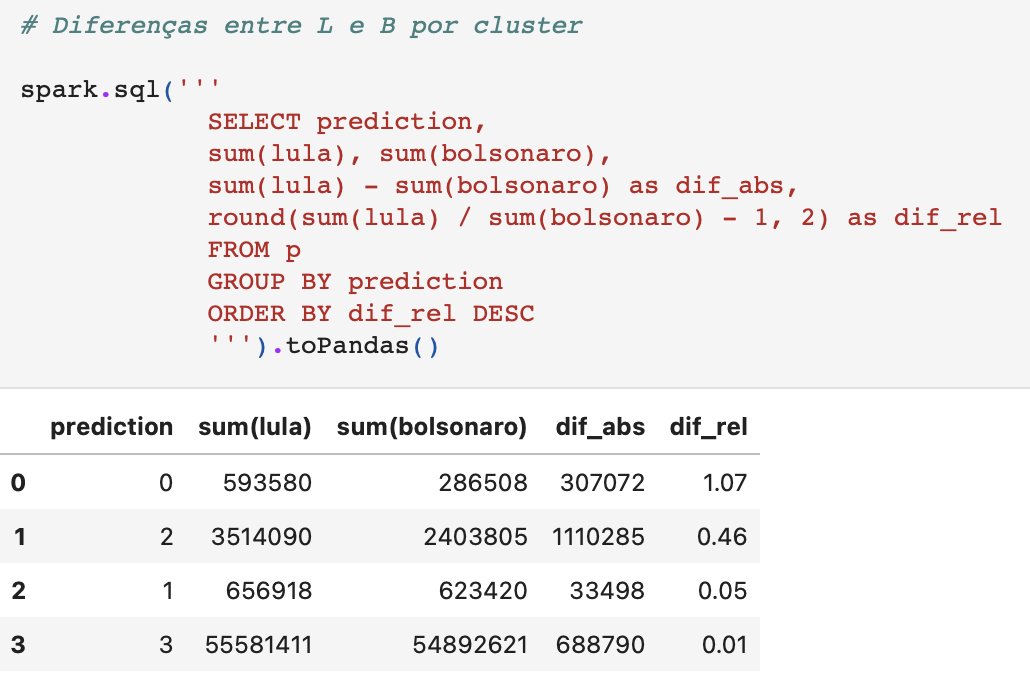
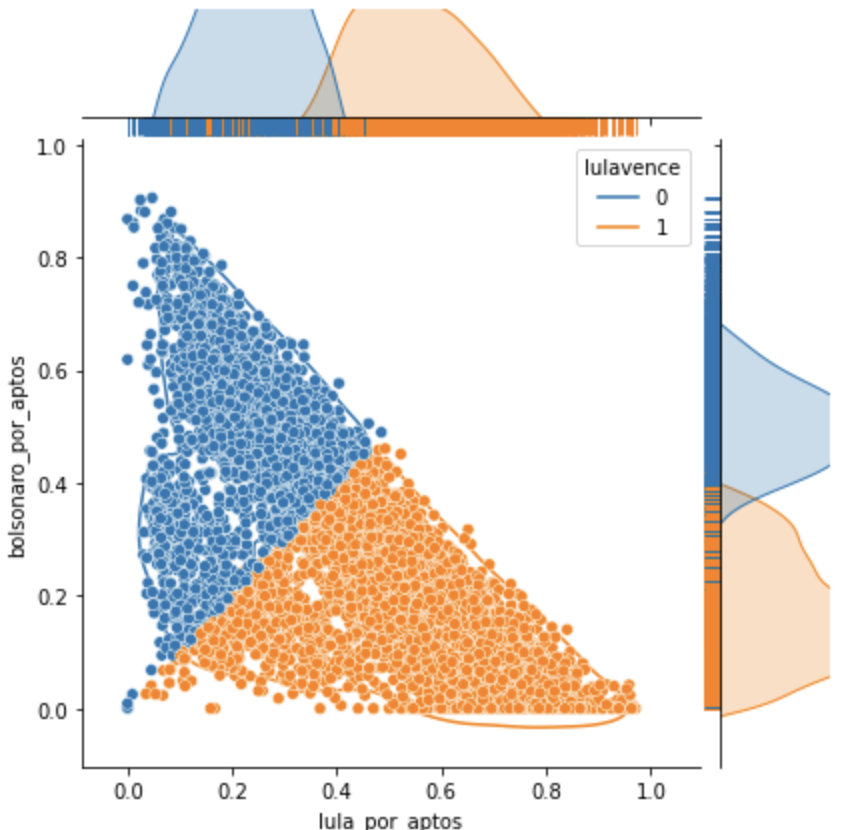
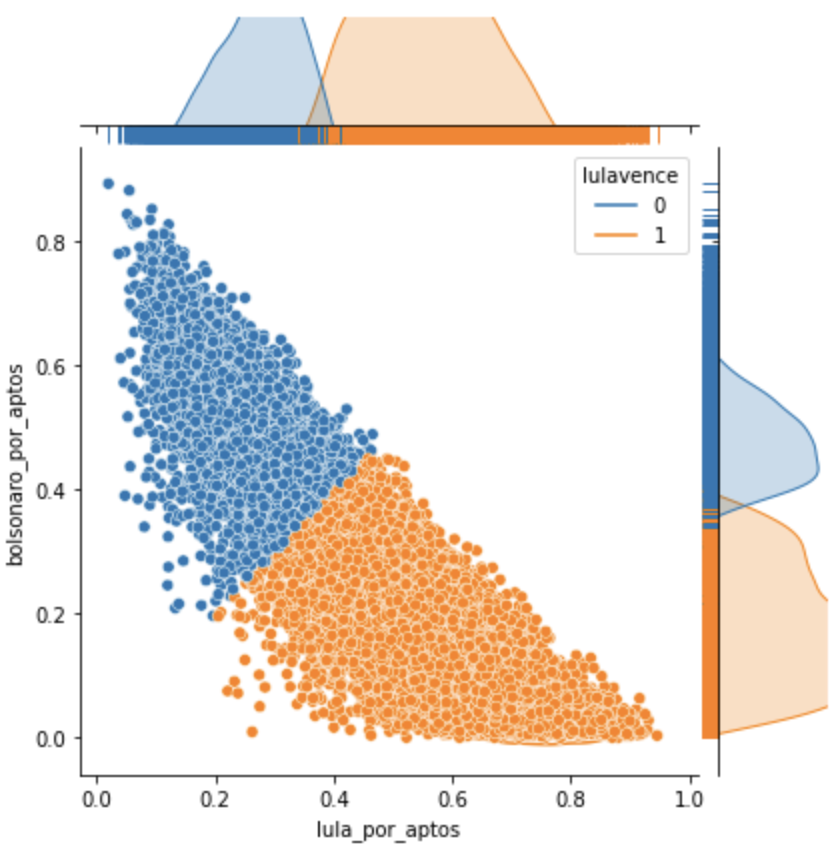
O L vence por larga escala no grupo 0.
Nesse grupo, L venceu com 107% de diferença para B.
No grupo 1 foi por 46%, no 2 por 5% e no 3 por apenas 1%
Os grupos 1, 2 e 3 somados deram num total de 1,45 milhões de votos de diferença. No 3, 688 mil de diferença apenas.
Nesse grupo, L venceu com 107% de diferença para B.
No grupo 1 foi por 46%, no 2 por 5% e no 3 por apenas 1%
Os grupos 1, 2 e 3 somados deram num total de 1,45 milhões de votos de diferença. No 3, 688 mil de diferença apenas.
O grupo 1 (lembrando que esses grupos foram todos dectados por inteligência artificial), há um volume insignificante de urnas novas, que nem aparecem no gráfico de frequência. A bimodalidade da frequência de urnas velhas aparece. Grande volume de abstenções em algumas seções.
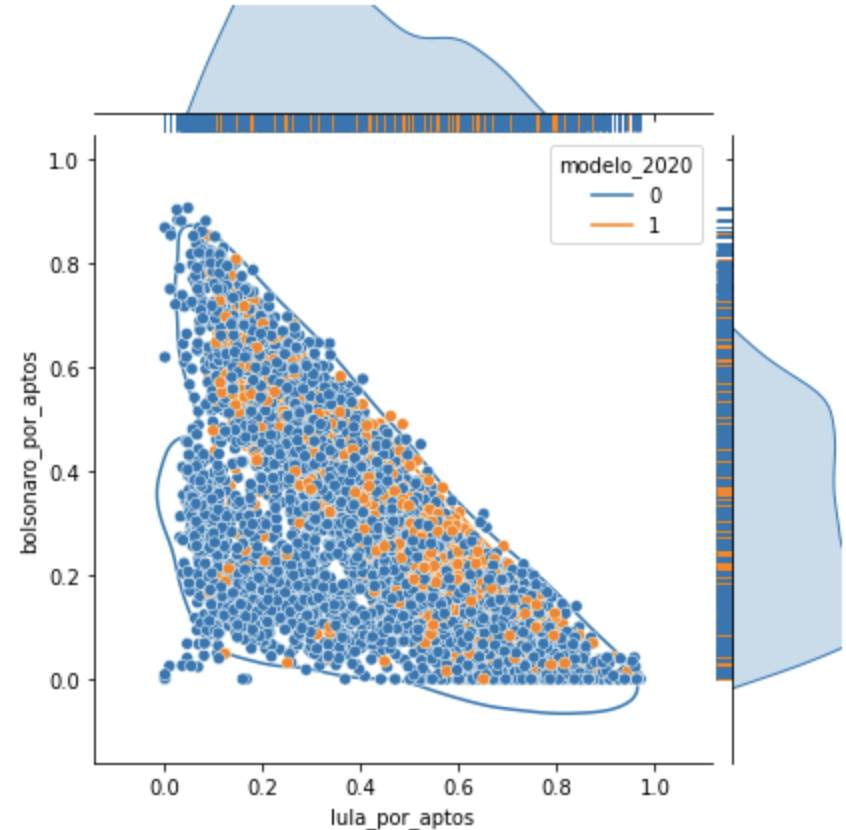
Analisando quem vence em cada seção, é possível notar que a frequência de L na área em que L vence (curvas à direita do gráfico) tem um gráfico um pouco diferente de uma distribuição normal.
Quando analisamos o que o algoritmo separou em termos de região, é possível ver que as seções de baixa abstenção são no exterior ou na região Norte. Mas há algumas também no sudeste e nordeste.
O formato do gráfico do grupo 1 é praticamente um triângulo retângulo, similar ao que seria, matematicamente, uma função trigonométrica. Curioso que a inteligência artificial tenha separado esses pontos dessa maneira.
Nas frequências, nota-se bimodal no exterior.
Nas frequências, nota-se bimodal no exterior.
O gráfico de modelo de urna desse grupo 1 apresenta mais distribuições um pouco diferentes do que vimos sob outros recortes.
O grupo 2 concentra ainda mais urnas com 0 em Bolsonaro e é mais parecido com os grupos em formato de triângulo que já falamos. Esse está mais para um triângulo isósceles. Aqui também é possível ver que as regiões significativas são Nordeste e Sudeste, sendo o NE mais frequente.
Quanto ao modelo, duas visões. A primeira com urnas novas vs antigas. E a segunda por modelo. Nesse grupo está clara a bimodalidade da curva das urnas antigas no gráfico à esquerda. Há poucas urnas novas. À direita, vemos por modelo. Algumas curvas bimodais.
No grupo 3, temos o formato de semicírculo que seria o mais esperado. Além disso, as curvas de frequência aparecem mais parecidas com as distribuições normais.
Nesse grupo há mais sudeste do que nordeste. Mas a frequência na região do B do NE é um pouco diferente da do B em SE.
Nesse grupo há mais sudeste do que nordeste. Mas a frequência na região do B do NE é um pouco diferente da do B em SE.

Quando analisamos modelo, há um pouco mais de equilíbrio nas frequências. A bimodalidade das urnas antigas é suavizada pela maior quantidade. Mas curvas mais parecidas em L e menos em B.
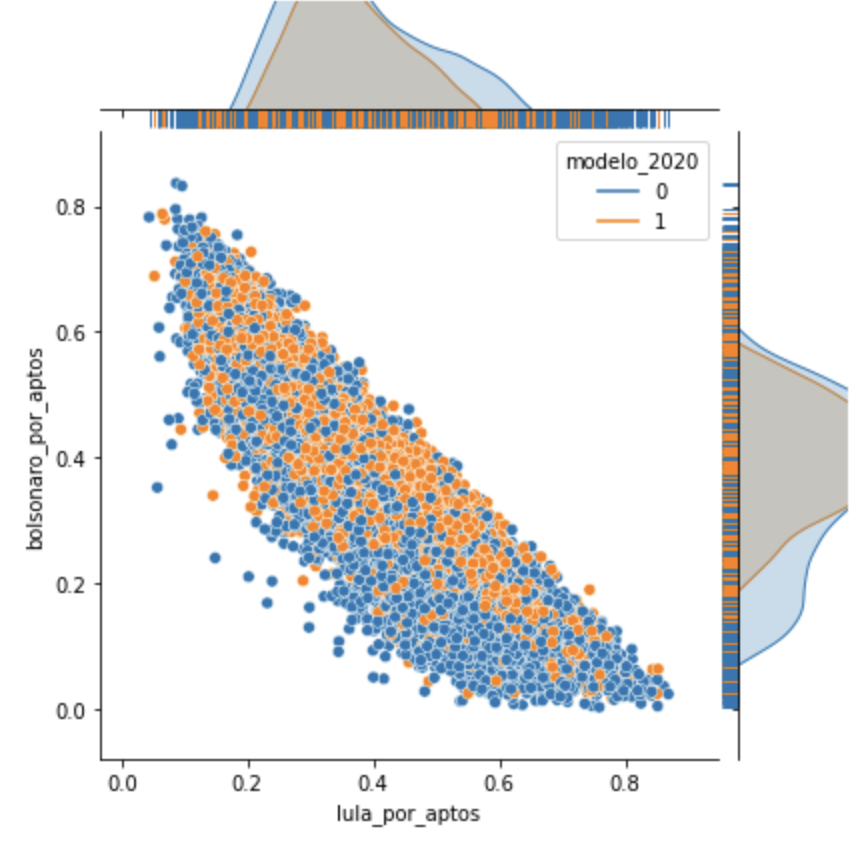
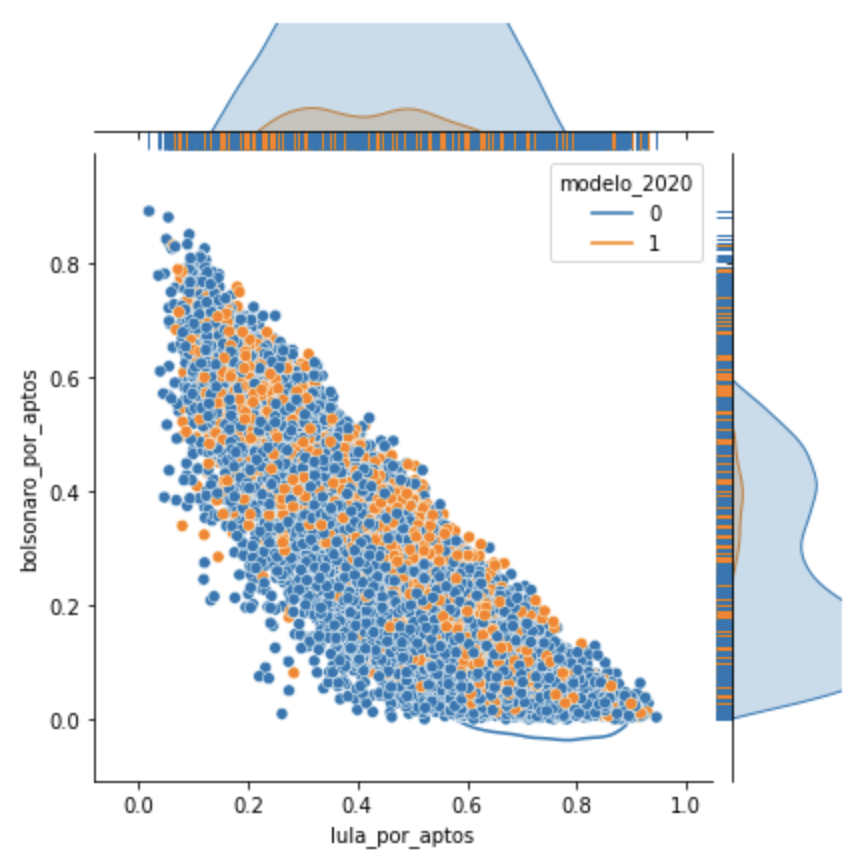
Por modelo, é possível notar que a inteligência artificial agrupo nesse grupo uma maior frequência de urnas novas.
Bastante intrigante que a própria inteligência artificial tenha feito essa distinção e separado nos grupos mesmo, nesse modelo, não tendo usado essa variável.
Bastante intrigante que a própria inteligência artificial tenha feito essa distinção e separado nos grupos mesmo, nesse modelo, não tendo usado essa variável.
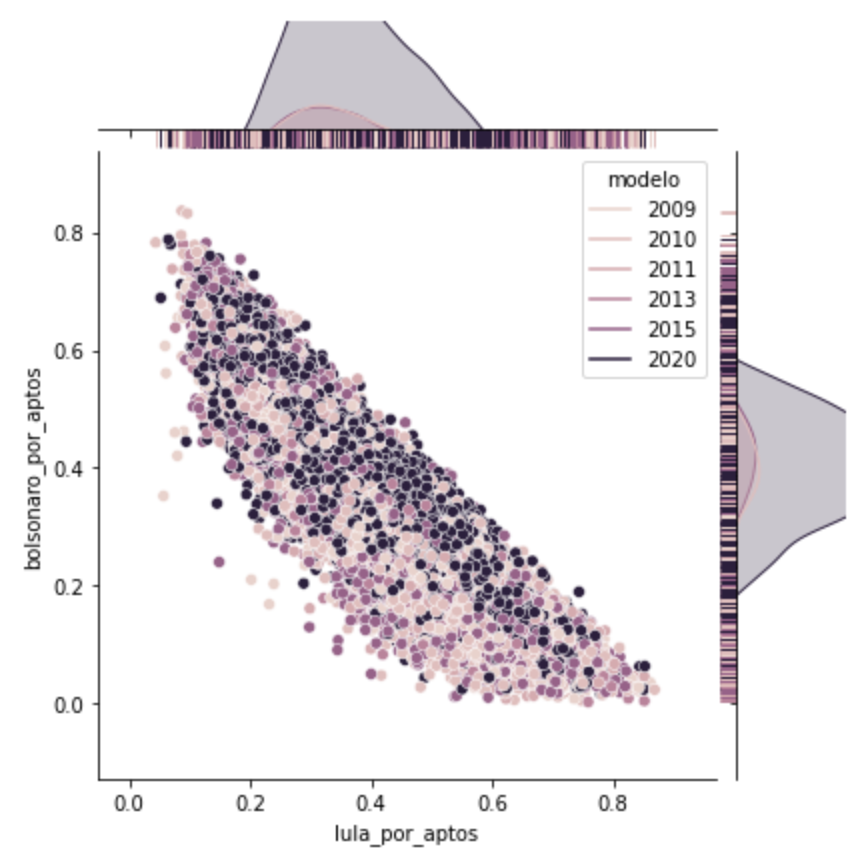
Ou seja, apenas considerando votos em B, L, brancos, nulos, abstenções e taxa de não habilitados biometria, o algoritmo foi capaz de segmentar um grupo sozinho contendo mais frequência de votos de urnas novas, e grupos menores contendo mais frequência em urnas antigas.
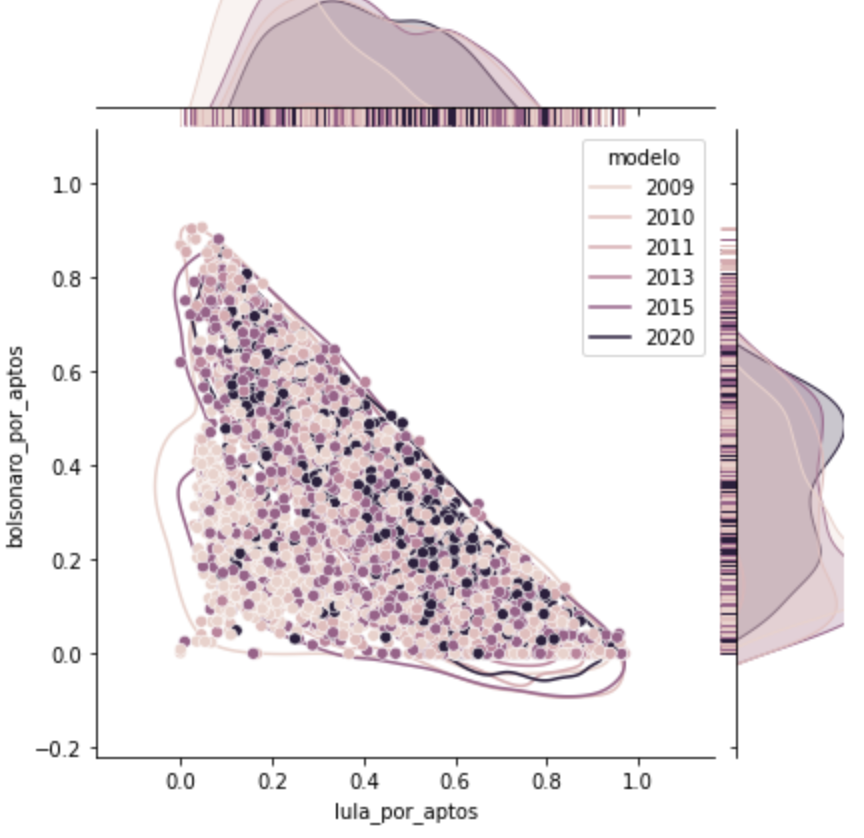
Outra curiosidade, nos grupos 0,1 e 2, ainda assim há diferenças grandes nos modelos mais antigos do que no modelo mais novo. Já no grupo 3, o mesmo ocorre, mas apenas nas urnas 2020 o Bolsonaro vence com 5 pontos de diferença.

Esse trabalho complementa o outro, pois utilizou outras variáveis. Aqui focamos apenas nas variáveis da eleição: votos em B, L, Brancos, Nulos, Abstenções e taxa de não habilitados biometria. Todos números da mesma ordem de grandeza (entre 0 e 1).
O fato de não ter usado nenhuma variável de modelo e a inteligência artificial acabar agrupando dessa maneira foi bastante surpreendente e positivo. Sinal de que sempre podemos nos impressionar do que os dados podem oferecer. Espero que essa nova thread tenha sido educativa!
Para ver o notebook completo no GitHub, basta clicar no link abaixo.
github.com
github.com
Caso queira rodá-lo, agora está bem fácil fazê-lo no Google Colab. Demora um pouco para rodar a parte de Machine Learning na versão gratuita e vc precisará colocar os datasets do repositório no seu Google Drive. Mas é bem tranquilo.
colab.research.google.com
colab.research.google.com
Importante: existe uma caixa em que estava tentando configurar Spark para usar GPU, mas não funcionou. De qualquer maneira, fica o desafio caso você queira contribuir. Por enquanto, use a caixa de CPU mesmo.
[]s e sucesso!
[]s e sucesso!
Loading suggestions...