

Merlin Dataloader is 119x faster than my own PyTorch Dataset + Dataloader combo!
This is revolutionary for tabular data 🥳
Let's take a closer look at what is going on.
This is revolutionary for tabular data 🥳
Let's take a closer look at what is going on.

First, a disclaimer.
It is very hard to do benchmarking in a fair way.
I am comparing how *I would* do things in pure Python/PyTorch vs what Merlin Dataloader does for me.
Here is the setup:
It is very hard to do benchmarking in a fair way.
I am comparing how *I would* do things in pure Python/PyTorch vs what Merlin Dataloader does for me.
Here is the setup:
I have a large dataframe with 152 million rows and two columns.
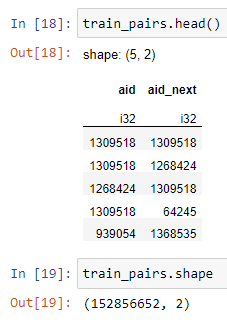
I create a simple Dataset and feed it to a PyTorch Dataloader.
For the Merlin Dataloader, I write the dataframe to disk and let Merlin figure it out.
For the Merlin Dataloader, I write the dataframe to disk and let Merlin figure it out.
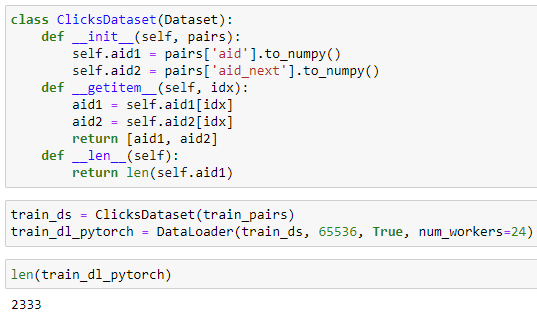

I guess I understand what is happening.
A lot of time and compute is spent on indexing into the numpy array and collating the 65536 examples per batch.
A lot of time and compute is spent on indexing into the numpy array and collating the 65536 examples per batch.

I *guess* I could figure it out myself and do it more efficiently?
I could maybe go with an iterable-style dataset and somehow shuffle data in chunks without indexing.
But frankly speaking, why would I write all this code? 🙂
With Merlin Dataloader I get speed for free!
I could maybe go with an iterable-style dataset and somehow shuffle data in chunks without indexing.
But frankly speaking, why would I write all this code? 🙂
With Merlin Dataloader I get speed for free!

So yeah, this is a new library by my team. 🙂
You can find it here: github.com
It supports TF, PyTorch and has some support for JAX.
You can find it here: github.com
It supports TF, PyTorch and has some support for JAX.

One reason it is so fast is because it utilizes Dask-based Merlin Datasets.
And I guess there are a couple of other things in Merlin Dataloaders that make it all (including memory transfer) super-fast.
But I would lie if I said I understood everything that is going on 🙂
And I guess there are a couple of other things in Merlin Dataloaders that make it all (including memory transfer) super-fast.
But I would lie if I said I understood everything that is going on 🙂
Will keep my 👀 and 👂s open to learn more!
And to whet your (and mine 😄) appetite a bit more, remember all those tabular data ops in NVTabular?
We now have a way to feed all that transformed data efficiently to TF, PyTorch, and JAX 🤯
Super excited, examples are coming! 🙌
And to whet your (and mine 😄) appetite a bit more, remember all those tabular data ops in NVTabular?
We now have a way to feed all that transformed data efficiently to TF, PyTorch, and JAX 🤯
Super excited, examples are coming! 🙌
Loading suggestions...