

Neural algorithm synthesis is done by giving models a human-crafted programming language and millions of sample programs. Recently, my lab looked at whether neural networks can synthesize algorithms on their own without these crutches. They can, with the right architecture. 🧵

Here's an algorithmic reasoning problem where standard nets fail. We train resnet18 to solve little 13x13 mazes. It accepts a 2D image of a maze and spits out a 2D image of the solution. Resnet18 gets 100% test acc on unseen mazes of the same size. But something is wrong…

If we test the same network on a larger maze it totally fails. The network memorized *what* maze solutions look like, but it didn’t learn *how* to solve mazes.
We can make the model synthesize a scalable maze-solving algorithm just by changing its architecture...
We can make the model synthesize a scalable maze-solving algorithm just by changing its architecture...
Let’s build a recurrent network that uses the same layer over and over. We’ll also have skip connections between the first layer of the network and the input to each recurrence. The recurrent block encodes an iteration that can be repeated indefinitely.
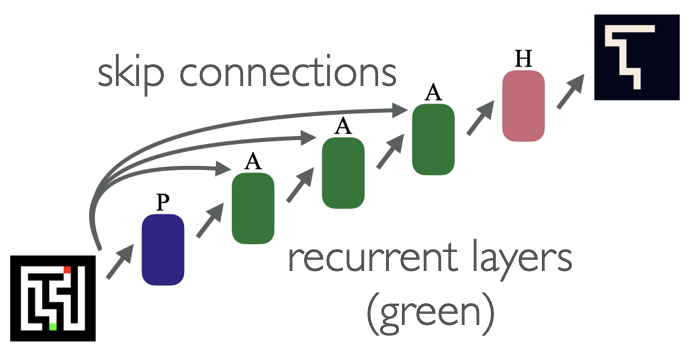
This recurrent structure forces the network to learn an algorithm. We can now scale up the power of the model *after* training is complete by increasing the number of recurrent iterations.

Now, a model trained *only* on 9x9 mazes for 30 recurrent iterations can generalize to this 801x801 maze at text time, provided we run the recurrent block for 25,000 iterations. That's over 100K conv ops.

Strangely, the network has also learned an error correcting code. If we corrupt the net's memory when it's halfway done, it will always recover. If we change the start/end point after the maze is solved, it draws the new solution in one shot with no wrong turns (shown below).

Networks can also learn algorithms for chess and prefix sum computation. For all these problems we use the same network and training loop, but different training data.
arxiv.org
See you all on thurs afternoon at @NeurIPSConf!
arxiv.org
See you all on thurs afternoon at @NeurIPSConf!
Loading suggestions...