

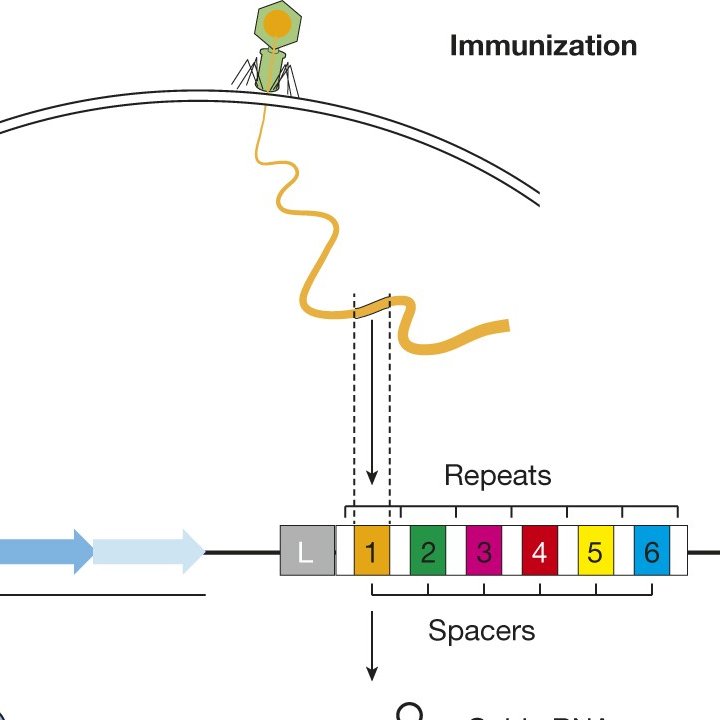
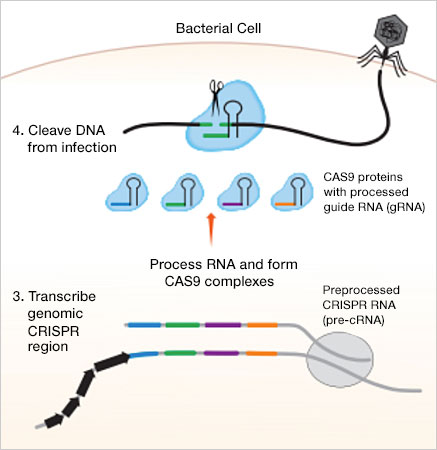
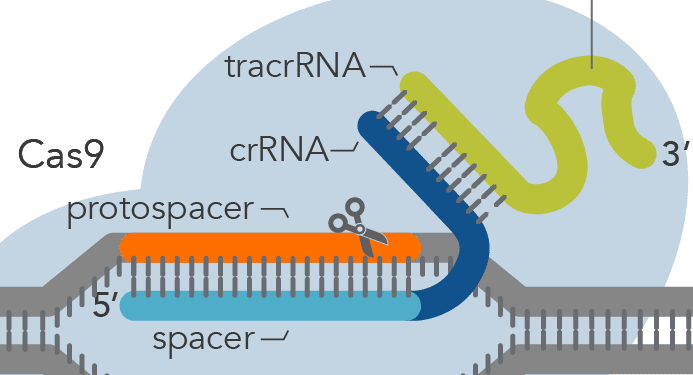
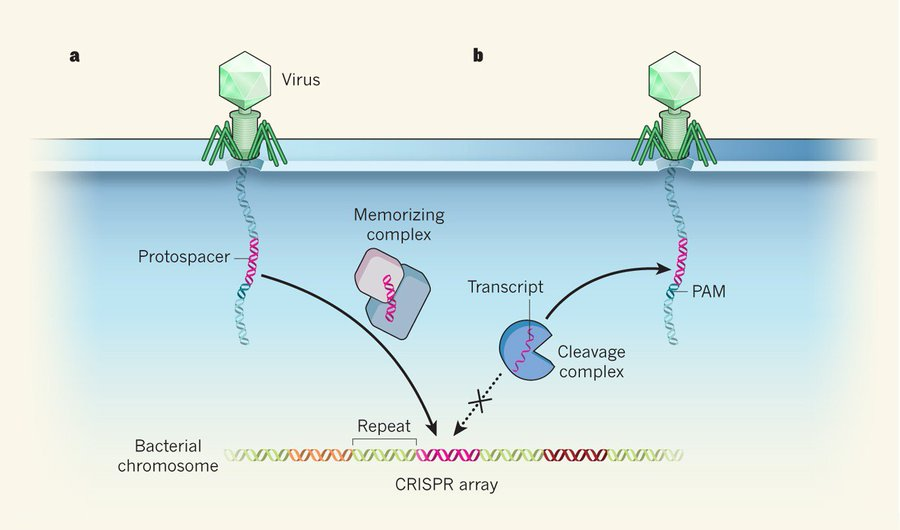
Here we will look at the discovery of CRISPR.


More from this author
DNA Structure and Packaging: Here we will finish of the structure of DNA and cover the packaging.
Intro to Transmission Genetics A look a the terms around inheritance and chromosomes.
Linked Genes Here we will look at gene linkages.
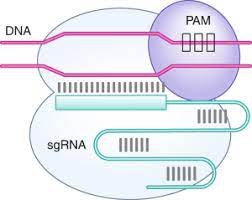
🧵Types of CRISPR Here we will look at the discovery of CAS9 and the many types of CAS enzymes.
Recent Threads
taekook taguan ng anak au wherein jk received a surprising gift from their xmas party… [ christmas special 🎄] https://t.co/WY3C450KpV

@HitWithAHeart I hear him before I see him. The weight of his steps on the stairs. Slower than usual. Measured. Like he’s already bracing for whatev...

(1/7) I'm not going to do a full trailer breakdown for Zach Cregger's Resident Evil film, since we have an early form of the script you can place a lo...

Nikola Jokic is 0-6 against 50+ win teams in the playoffs. https://t.co/l5hCeVCoUj

Uni is a fighter! https://t.co/AXkBVFJ2My

Triggered girl at comedy show… https://t.co/z1BC2qG7Rd

Popular Threads
Here's 40 TikTok hooks that could make you go viral. (Not in any particular order) //THREAD//

Winning the Chevening Scholarship + 12 Strong Samples of the Chevening Essay There are four important Essays on the Chevening Scholarship application...

A thread: Pakistani newspaper Dawn's front pages from 4th december 1971 to 20 December to see how they kept their own people in the dark. This was on...

ICT’s 2022 Mentorship Summarized: https://t.co/zFJCgIfDAR

These are the 41 most powerful tenants of Tateism for a man to live by. Wether you are Christian, Muslim; It doesn’t matter if you are strong, weak...

The ICT Mentorship Core Content Month 1 Summarized: https://t.co/6tXJxPMDhm