

Tune-A-Video: One-Shot Video Generation
A text-to-video model to generate videos from text prompts via an efficient one-shot tuning of pre-trained text-to-image diffusion models.
Here is my quick summary ⬇️
A text-to-video model to generate videos from text prompts via an efficient one-shot tuning of pre-trained text-to-image diffusion models.
Here is my quick summary ⬇️

It leverages pre-trained text-to-image diffusion models extending spatial self-attention to spatio-temporal cross-frame attention with an efficient tailored Sparse-Causal Attention module.
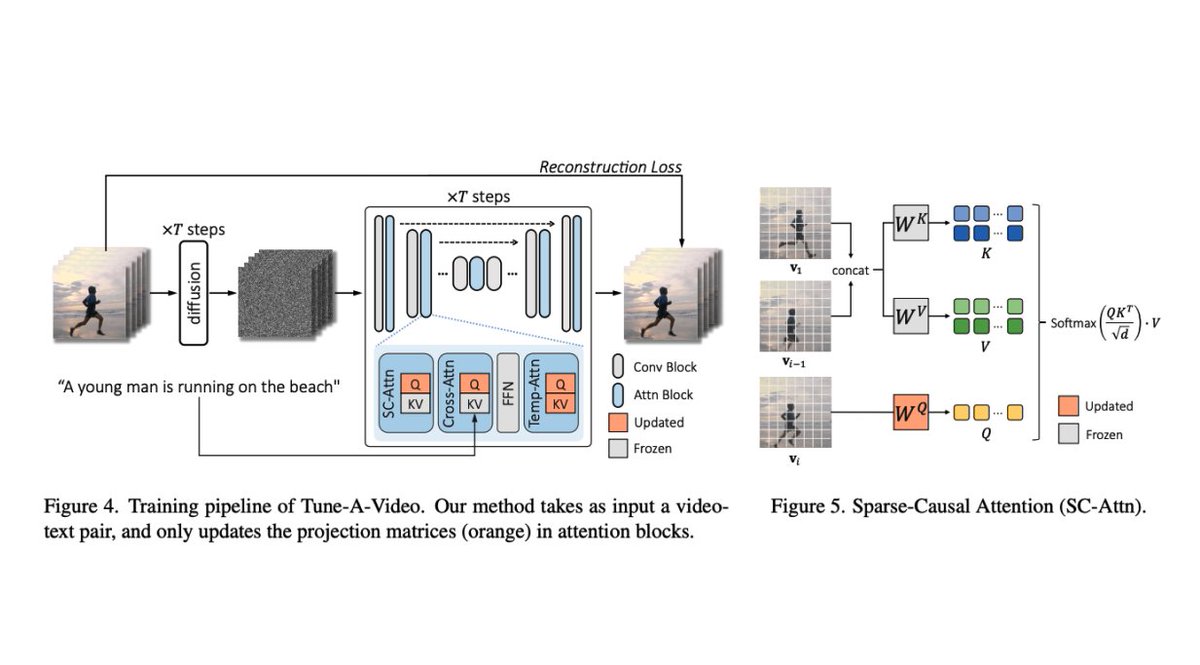
The current paradigm relies on large-scale text-video datasets for fine-tuning which is computationally expensive.
In contrast, only a single text-video pair is provided for training the proposed open-domain T2V generator.
In contrast, only a single text-video pair is provided for training the proposed open-domain T2V generator.

Check out some of the quantitative and qualitative results below. CogVideo, based on CogView2, consists of 9.4B parameters which is around 6× larger than the proposed Tune-A-Video model.

Overall, this is a great paper proposing the feasibility of one-shot video generation with impressive results.
I also like the idea that we are already focusing on computational efficiency for T2V.
Paper: arxiv.org
Website: tuneavideo.github.io
I also like the idea that we are already focusing on computational efficiency for T2V.
Paper: arxiv.org
Website: tuneavideo.github.io
Loading suggestions...