

This is awesome.
Tune-A-Video is a new method that allows one-shot tuning of image diffusion models for Text-to-Video generation.
📄 Paper: arxiv.org
⚙️ Project: tuneavideo.github.io
🛠️ Code: Coming Soon
👇More examples and TLDR below
Tune-A-Video is a new method that allows one-shot tuning of image diffusion models for Text-to-Video generation.
📄 Paper: arxiv.org
⚙️ Project: tuneavideo.github.io
🛠️ Code: Coming Soon
👇More examples and TLDR below

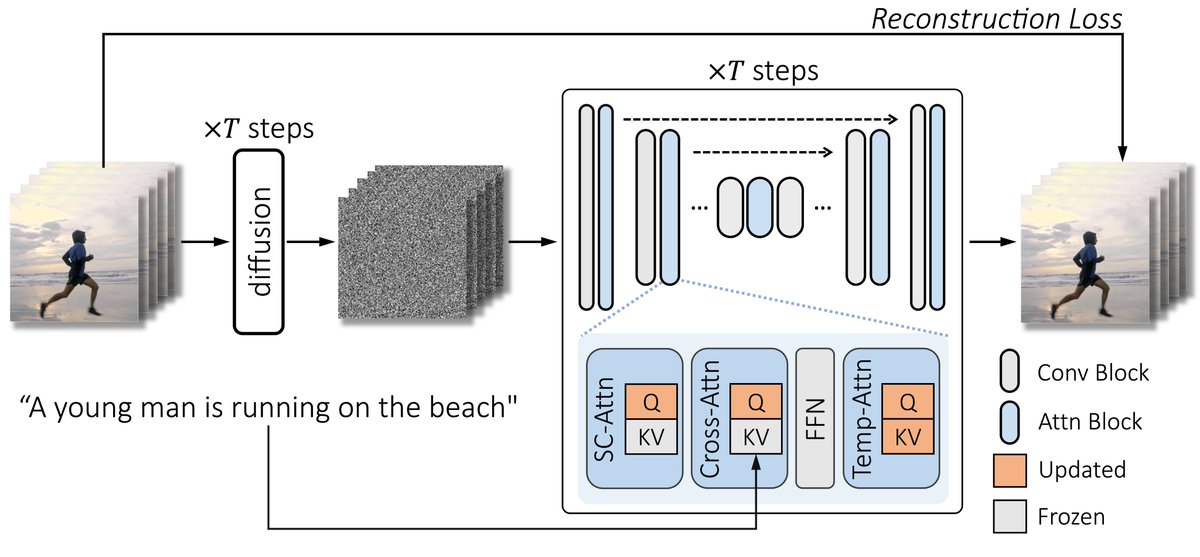
TLDR: Researchers extended text-to-image diffusion to generate multiple images. To learn continuous motion, they propose Tune-A-Video with a tailored Sparse-Causal Attention, which generates videos from text prompts via an efficient one-shot tuning of pretrained T2I models.
Training Video: "A dog is running on the grass"

Training Video: "A man is dribbling a basketball on the court"

Method overview: Training pipeline of Tune-A-Video. The method takes as input a video-text pair, and only updates the projection matrices (orange) in attention blocks.

Authors: Jay Zhangjie Wu,@ge_yixiao, Xintao Wang, Stan Weixian Lei, @YuchaoGu, Wynne Hsu, Ying Shan, Xiaohu Qie, @MikeShou1
Loading suggestions...