

Within the LLM x startup world, the idea of a "data engine" is often discussed as a means of building a moat.
The idea is to gather data as your model interacts with the real world => leverage these experiences to improve the model for your specific task
The idea is to gather data as your model interacts with the real world => leverage these experiences to improve the model for your specific task
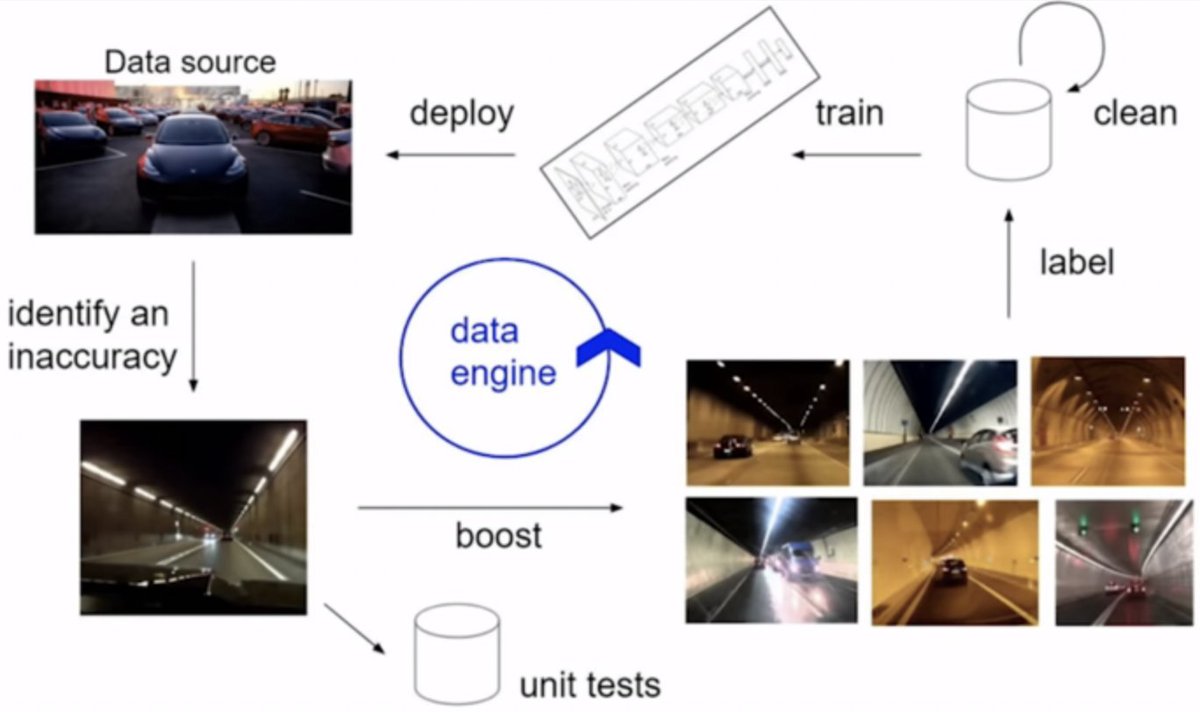
The defensibility comes from the idea that the models that amass more experience (i.e. are deployed earlier/broader) will improve faster over time, compounding returns.
This assumes that deployment in the wild is the best way to gather the "fuel" for your data engine, however.
This assumes that deployment in the wild is the best way to gather the "fuel" for your data engine, however.
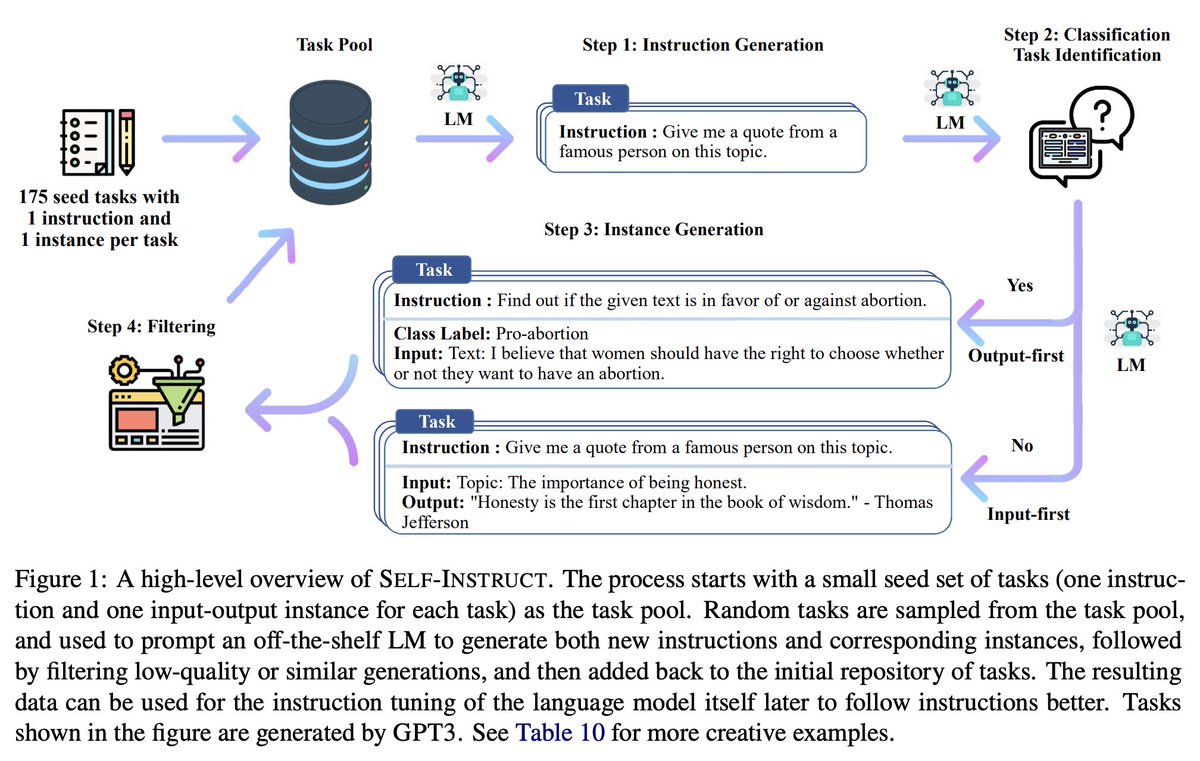
In SELF-INSTRUCT (2022), the authors have GPT-3 generate a set of 82k samples for "instruction tuning" (essentially what OpenAI has claimed makes their models better/more aligned)
This is basically sets of (task definition, pos/neg example, input/output instances)
This is basically sets of (task definition, pos/neg example, input/output instances)
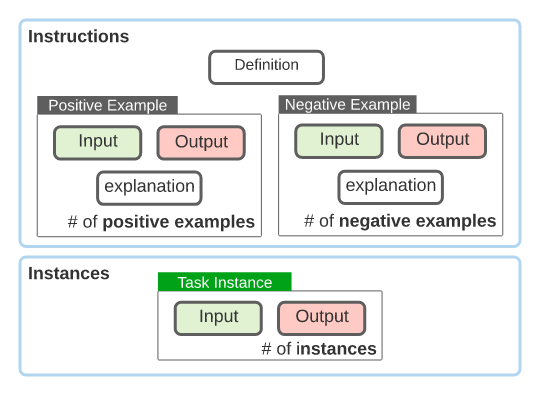
They find that GPT-3 is able to generate a diverse set of new tasks to instruction tune itself with:

And critically, they show that actually running instruction tuning with these GPT-3-generated samples performs as well as InstructGPT
That is, using *synthetic* data for instruction tuning can perform as well as a traditional "data engine"!
That is, using *synthetic* data for instruction tuning can perform as well as a traditional "data engine"!

Their process is relatively simple and essentially involves an iterative cycle of generating and filtering samples for instruction tuning.
Seems straightforward to reproduce even on a closed model like OpenAIs' GPT ecosystem (as the authors did here)
Seems straightforward to reproduce even on a closed model like OpenAIs' GPT ecosystem (as the authors did here)


This is very promising as an approach for startups and resource-poor outfits trying to achieve high performance IMO
Barrier to entry is low: literally see if you can generate synthetic tasks/samples in your domain for instruction tuning, then fine-tune + evaluate.
Barrier to entry is low: literally see if you can generate synthetic tasks/samples in your domain for instruction tuning, then fine-tune + evaluate.
Loading suggestions...