

Day 57 of #60daysOfMachineLearning
🔷 Training, validation, test data 🔷
In machine learning, it is important to divide your data into three sets: training, validation, and test.
🧵 👇
🔷 Training, validation, test data 🔷
In machine learning, it is important to divide your data into three sets: training, validation, and test.
🧵 👇
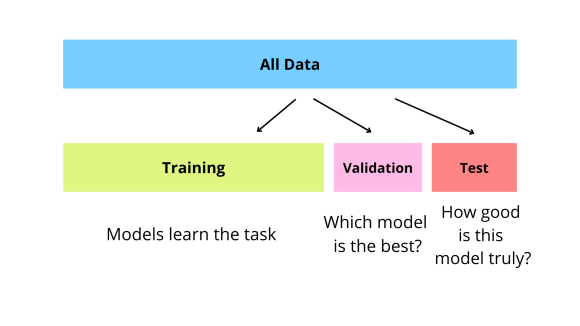
The training set is used to train the model. The model is presented with examples from the training set and adjusts its parameters to minimize the error on these examples.
The validation set is used to evaluate the model during training. The model is presented with examples from the validation set and the error on these examples is used to guide the training process.
The test set is used to evaluate the final performance of the model. The model is presented with examples from the test set and the error on these examples is used to measure the generalization performance of the model.
It is important to use a separate validation and test set to ensure that the model is not overfitting to the training data. Overfitting occurs when the model has learned the training data too well and is not able to generalize to new examples.
The size of the training, validation, and test sets can vary depending on the size of the dataset and the specific task. A common split is to use 80% of the data for training, 10% for validation, and 10% for testing.
It is important to shuffle the data before dividing it into training, validation, and test sets to ensure that the data is representative of the entire dataset.
Loading suggestions...