

🗄️🗄️Will the next generation of LLMs have native data structures for storing insights?
Pre-LLM era research has some interesting ideas here.
Two of my favorite, both exactly what they sound like:
- Stack-Augmented Recurrent NNs
- Neural Turing Machine
More 👇
Pre-LLM era research has some interesting ideas here.
Two of my favorite, both exactly what they sound like:
- Stack-Augmented Recurrent NNs
- Neural Turing Machine
More 👇
Current LLMs have finite context length - the amount of input it can "consider" simultaneously.
This is a challenge if you want to run inference over:
- An entire codebase
- All of your Notion/Drive/Dropbox
- An entire social media site
Etc.
This is a challenge if you want to run inference over:
- An entire codebase
- All of your Notion/Drive/Dropbox
- An entire social media site
Etc.
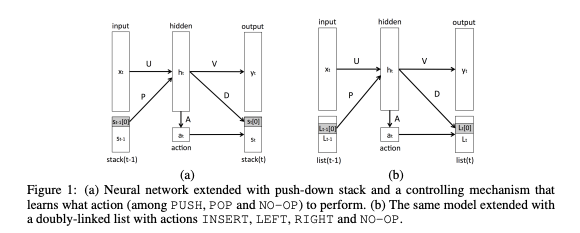
The idea in these (and other) approaches is to strap on some sort of an external data structure that a sequence model learns to store/retrieve info from
For instance, you can teach a regular RNN to output actions it wants to perform on a stack, like push/pop
For instance, you can teach a regular RNN to output actions it wants to perform on a stack, like push/pop
A trivial version of this is that at every timestep an RNN gets to output a vector that gets summed into a fixed buffer, then it gets to read that buffer as part of input at the subsequent timestep
You can do much better though.
You can do much better though.
In Neural Turing Machines, you build an end-to-end differentiable system analogous to a Turing machine or the Von Neumann architecture
End-to-end differentiable matters as it allows you to train it via gradient descent aka backpropagation, which we know works well.
End-to-end differentiable matters as it allows you to train it via gradient descent aka backpropagation, which we know works well.

In a NTM, you give a recurrent neural network access to a (fixed) external "memory" matrix which it can both read from and write to at each time step
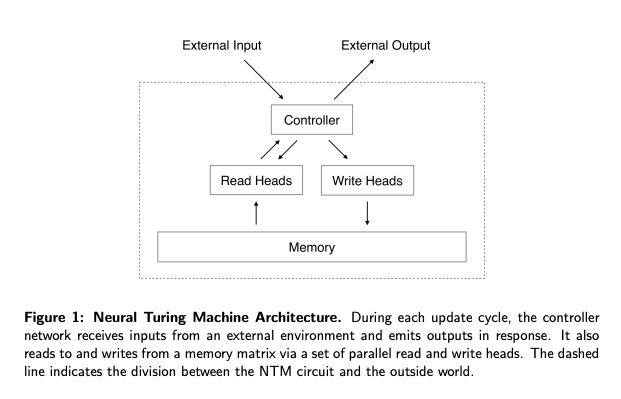
Both read and write are done via computing (separate) attention values over the memory buffer, then applying a function to update values or retrieve them as input to the main "controller" network, respectively.
The below explains this more eloquently
The below explains this more eloquently

And I might be wrong, but did these guys invent the idea of attention and key vectors? I don't remember ever seeing it prior to this.
PhDs weigh in here please.
PhDs weigh in here please.
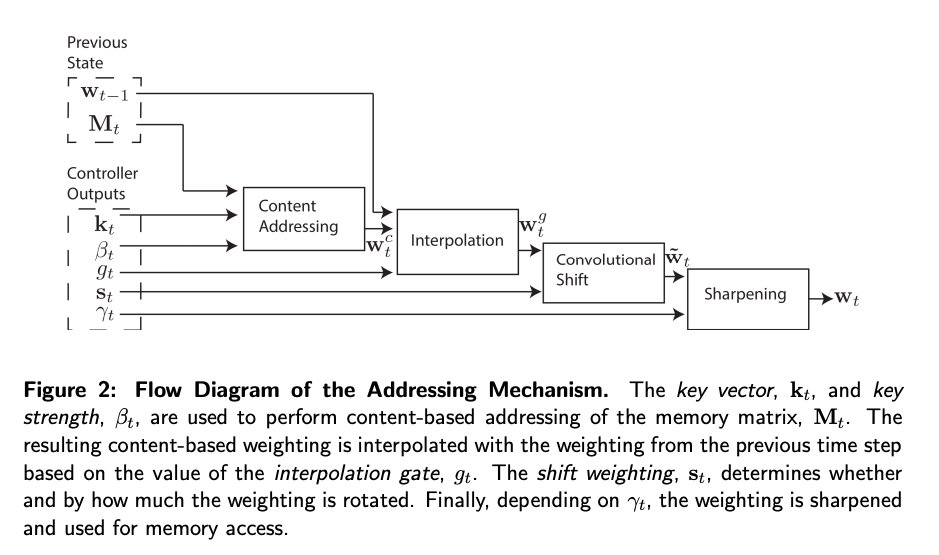
By modern standards the performance of this isn't remarkable but it definitely *feels* like something that would kick ass.
No reason this wouldn't generalize to networks with transformers as the building blocks as well, i.e. GPT, T5, OPT etc.
No reason this wouldn't generalize to networks with transformers as the building blocks as well, i.e. GPT, T5, OPT etc.
Stack-Augmented Recurrent Neural Nets
Idea is you infer a push/pop operation at every timestep, then apply this operation to a datastructure that looks like a differentiable stack
Idea is you infer a push/pop operation at every timestep, then apply this operation to a datastructure that looks like a differentiable stack

In order to make the stack differentiable, instead of taking a discrete push/pop operation at every timestep, you basically take a combination of the two, where their relative contribution to the output is defined by a parametrized function of the NN's input


In conclusion:
Two cool techniques that were demonstrated a while ago for strapping some sort of a data structure to a sequence model (way smaller than LLMs), then trained with backpropogation
Two cool techniques that were demonstrated a while ago for strapping some sort of a data structure to a sequence model (way smaller than LLMs), then trained with backpropogation
No reason this couldn't happen with LLMs too
And when it does, many problems relating to context overflow will be suddenly tractable
🙏
And when it does, many problems relating to context overflow will be suddenly tractable
🙏
Loading suggestions...