

Computer vision had a lot of quick wins in bootstrapping massive datasets over the last decade:
🎨 Image colorization - convert color photos to B&W
🔬 Image superresolution - downsample real photos
etc.
1/
developer.nvidia.com
🎨 Image colorization - convert color photos to B&W
🔬 Image superresolution - downsample real photos
etc.
1/
developer.nvidia.com
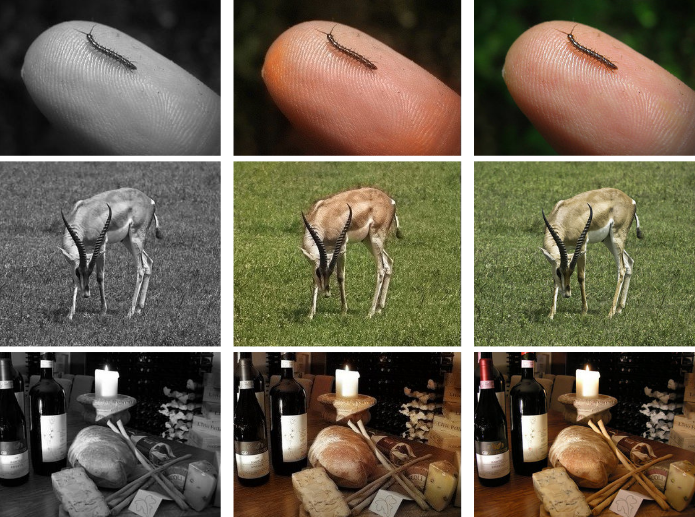
I see this as fundamentally similar to the pre-training stage of LLMs, where you basically bootstrap a huge dataset of (prefix, next word) by slicing up real texts.
2/
2/
Interesting to see now that Facebook has released a 1B segmentation mask dataset, SA-1B, *generated by their Segment Anything model*
This is conceptually similar to releasing a large set of input/output pairs of GPT-4 for other models' consumption.
3/
ai.facebook.com
This is conceptually similar to releasing a large set of input/output pairs of GPT-4 for other models' consumption.
3/
ai.facebook.com
It looks like models will increasingly have mixed diets of real data and extensions to it, either bootstrapped by quick win heuristics (convert to B&W) or by prompting other models
Loading suggestions...