

Unpacking the lifecycle of a rollup transaction: 🧵
Now (Centralized Sequencers)
vs.
Future (Modular everything)
Now (Centralized Sequencers)
vs.
Future (Modular everything)

First, Current centralized rollups:
The tx journey begins when you perform an action on a rollup dApp and click "Sign" on your wallet.
The wallet is your interface.
It's how you interact with the blockchain network.
The tx journey begins when you perform an action on a rollup dApp and click "Sign" on your wallet.
The wallet is your interface.
It's how you interact with the blockchain network.

Behind the scenes, the wallet interacts with the rollup RPC node to check the state of the rollup.
If blockchains are like a house, RPC nodes are like the doors to that house.
It's how anyone can read the blockchain ledger.
If blockchains are like a house, RPC nodes are like the doors to that house.
It's how anyone can read the blockchain ledger.

The rollup RPC sends the tx (as "pending tx") to a reservoir of txs called mempool or memory pool.
Mempool is a p2p network of nodes that share a view of these txs - but the txs are unordered here.
Now, the centralized rollup operator comes into play:
Mempool is a p2p network of nodes that share a view of these txs - but the txs are unordered here.
Now, the centralized rollup operator comes into play:
This operator (or 'sequencer') performs multiple tasks:
1. It orders the txs and creates a block
2. It sends a 'soft confirmation' to the user saying that the tx has been included in an L2 block and will be eventually included in an L1 block as well
1. It orders the txs and creates a block
2. It sends a 'soft confirmation' to the user saying that the tx has been included in an L2 block and will be eventually included in an L1 block as well
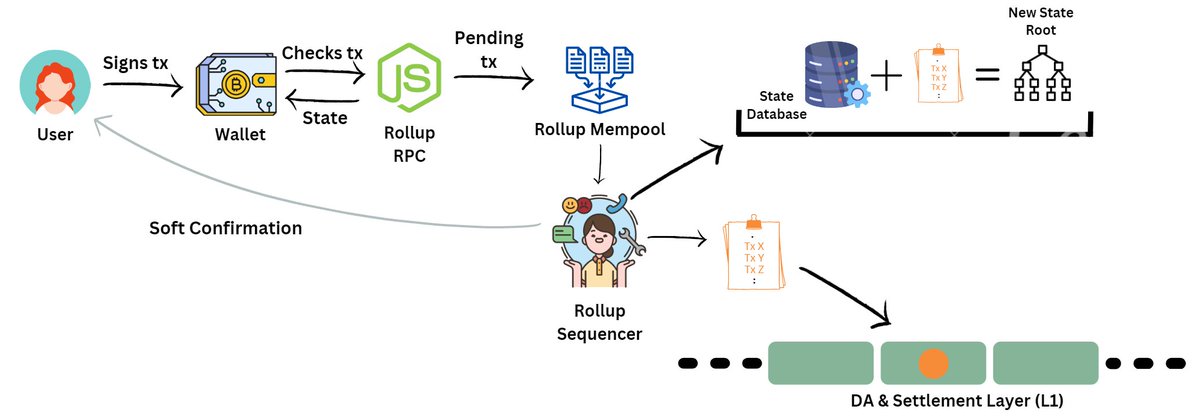
3. It compresses the tx batch and posts it to the DA layer - (for simplicity, say it's the same as the settlement layer (L1), eg. Ethereum)
4. It executes the block of txs to get a new state root
Previous state root + new tx data = new state root
4. It executes the block of txs to get a new state root
Previous state root + new tx data = new state root
The new state root is then gossiped amongst the various nodes of the network that update the rollup state.
The base layer Ethereum runs a light client of the rollup which also receives this gossiped new state.
The base layer Ethereum runs a light client of the rollup which also receives this gossiped new state.
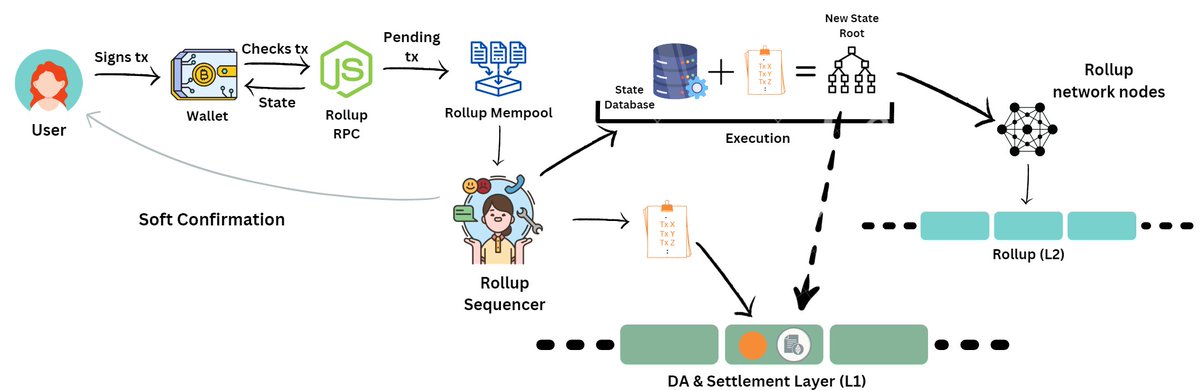
The rollup smart contract on Ethereum also verifies any validity proofs (in the case of ZKRUs) or fraud proofs (in the case of ORUs) and then updates the state of the Rollup in the L1 database.
At this point, finality is achieved.
The tx journey is complete.
At this point, finality is achieved.
The tx journey is complete.
Makes sense?
Pretty simple till here.
Give one central operator the responsibility to do everything and the process looks simple.
Pretty simple till here.
Give one central operator the responsibility to do everything and the process looks simple.
But centralization is the first thing we're trying to avoid with blockchains!
Here are a few reasons why centralized rollup sequencers aren't ideal- They can:
- Censor txs
- Do monopolistic pricing
- Frontrun user txs to generate MEV
Here are a few reasons why centralized rollup sequencers aren't ideal- They can:
- Censor txs
- Do monopolistic pricing
- Frontrun user txs to generate MEV
In addition, having siloed rollups fragments liquidity across different rollups.
So how do we solve this?
Modularity!
So how do we solve this?
Modularity!
In the modular world that the Ethereum ecosystem is headed towards, the execution responsibilities of the centralized rollup operator would be abstracted away and performed by separate layers.
In this era, the tx lifecycle would change as follows:
In this era, the tx lifecycle would change as follows:
The journey begins again with the user signing the tx through a wallet.
The wallet checks the state using the rollup RPC and sends the "pending" tx to a mempool.
However, instead of sending it to the rollup-specific mempool, it sends the tx to the *shared sequencer* mempool.
The wallet checks the state using the rollup RPC and sends the "pending" tx to a mempool.
However, instead of sending it to the rollup-specific mempool, it sends the tx to the *shared sequencer* mempool.
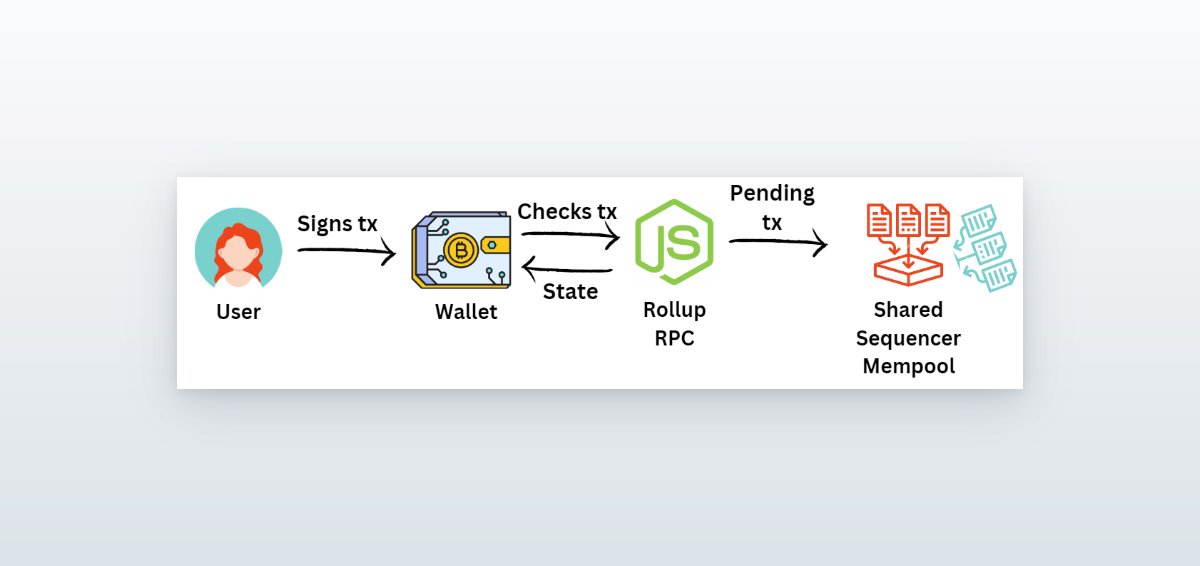
The shared sequencer mempool receives txs from several different rollups!
Entities called Searchers keep track of this mempool to search for any MEV opportunities.
Entities called Searchers keep track of this mempool to search for any MEV opportunities.
Searchers are usually heavy-duty full nodes that do the following:
- Pick up some txs,
- Add their own txs,
- Create a bundle of txs to extract MEV
- Send the bundle to "builders"
- Bid an amount for their bundle to be selected by the builders
- Pick up some txs,
- Add their own txs,
- Create a bundle of txs to extract MEV
- Send the bundle to "builders"
- Bid an amount for their bundle to be selected by the builders
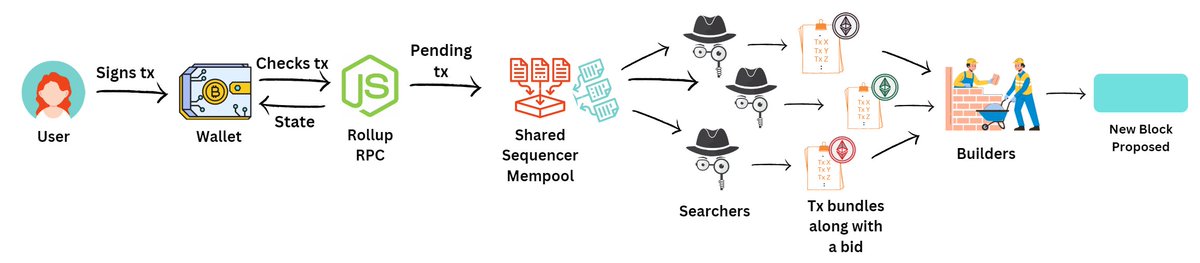
Builders are also heavy-duty full nodes that take the bundle from the searcher who bids the highest amount
They include the bundle(s) in addition to other txs from the mempool into a block and "propose" this block to the Shared Sequencer
They include the bundle(s) in addition to other txs from the mempool into a block and "propose" this block to the Shared Sequencer
The Shared sequencer now does the following:
1. It picks the best block (highest bid/follows all rollups' criteria etc.)
2. It sends a soft confirmation of the inclusion of tx to the users of all the rollups
2. It writes the ordered block of data to the DA layer
1. It picks the best block (highest bid/follows all rollups' criteria etc.)
2. It sends a soft confirmation of the inclusion of tx to the users of all the rollups
2. It writes the ordered block of data to the DA layer
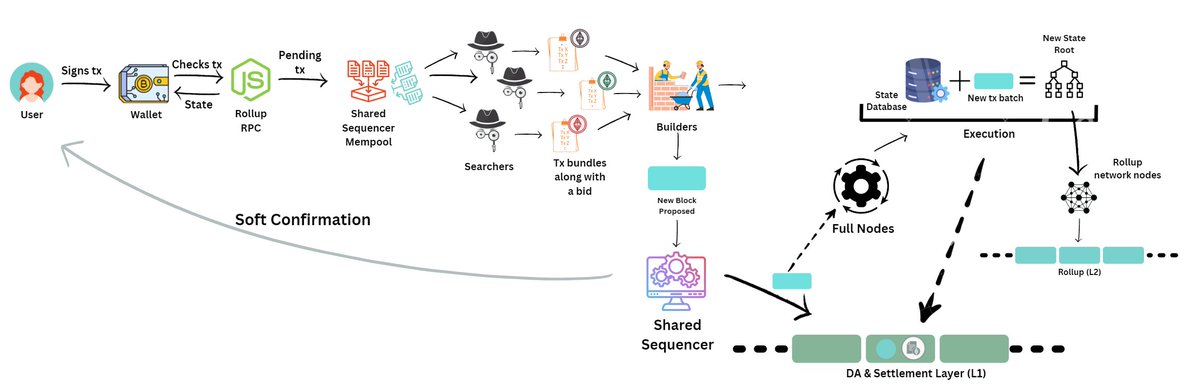
Then, the rollup’s full nodes:
- Retrieve a block from the shared sequencer or the base layer,
- Check it against their fork choice rule,
- Filter out txs from other rollups, and
- Use STF (state transition function) to apply the resultant subset of txs to their previous state.
- Retrieve a block from the shared sequencer or the base layer,
- Check it against their fork choice rule,
- Filter out txs from other rollups, and
- Use STF (state transition function) to apply the resultant subset of txs to their previous state.
This generates the new state of the rollup which is then gossiped to the light clients.
Meanwhile, the process on the L1 smart contract is the same:
Verify for validity proofs or fraud proofs and update the database.
Meanwhile, the process on the L1 smart contract is the same:
Verify for validity proofs or fraud proofs and update the database.
And that's all there is!
Since the shared sequencer doesn't perform execution, it can be "stateless" - this makes them easy to decentralize!
And because multiple rollups can share one decentralized sequencer, this also improves interoperability between them.
Since the shared sequencer doesn't perform execution, it can be "stateless" - this makes them easy to decentralize!
And because multiple rollups can share one decentralized sequencer, this also improves interoperability between them.
@AstriaOrg and @EspressoSys are two amazing teams building shared sequencers for the modular future!
Flashbots is building a 'decentralized builder' - 'SUAVE'
I hope this helps in understanding the recent CT discourse around sequencers, proposers, builders, etc.
Flashbots is building a 'decentralized builder' - 'SUAVE'
I hope this helps in understanding the recent CT discourse around sequencers, proposers, builders, etc.
If you want to learn more about the economics, benefits, and tradeoffs of Shared Sequencers, check out this article by @0xRainandCoffee
Also highly recommend @jon_charb's comprehensive post on everything rollups:
Loading suggestions...