

LLMs are revolutionizing the AI world, and attention is everywhere!
Today, I'll clearly explain how self-attention works! 🚀
A Thread 🧵👇
Today, I'll clearly explain how self-attention works! 🚀
A Thread 🧵👇

Computer are good with number❗️
In NLP we convert the sequence of words into token & then token to embeddings.
You can think of embedding as a meaningful representation of each token using a bunch of numbers.
Check this out 👇
In NLP we convert the sequence of words into token & then token to embeddings.
You can think of embedding as a meaningful representation of each token using a bunch of numbers.
Check this out 👇

Now, for a language model to perform at a human level, it's not sufficient for it to process these tokens independently.
It's also important to understand the relationship between them!
Check this 👇
It's also important to understand the relationship between them!
Check this 👇

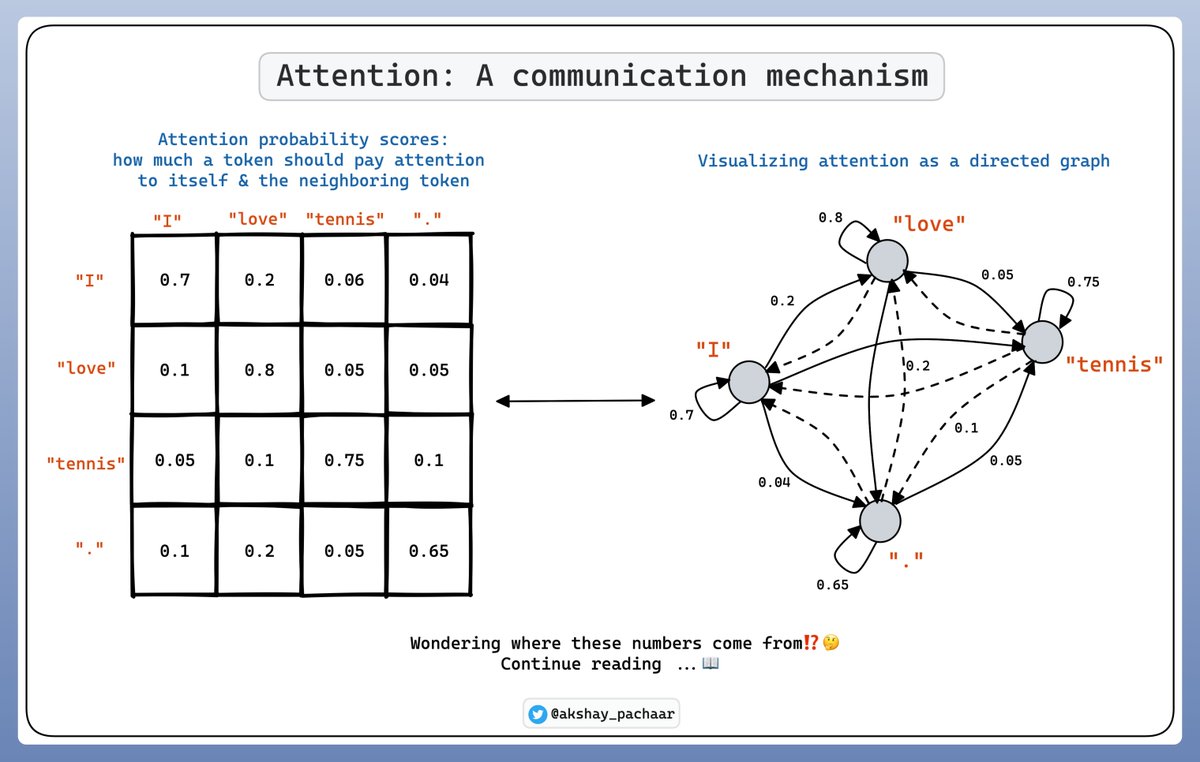
In the self-attention, relationships between tokens are expressed as probability scores.
Each token assigns the highest score to itself and additional scores to other tokens based on their relevance.
Check this out 👇
Each token assigns the highest score to itself and additional scores to other tokens based on their relevance.
Check this out 👇
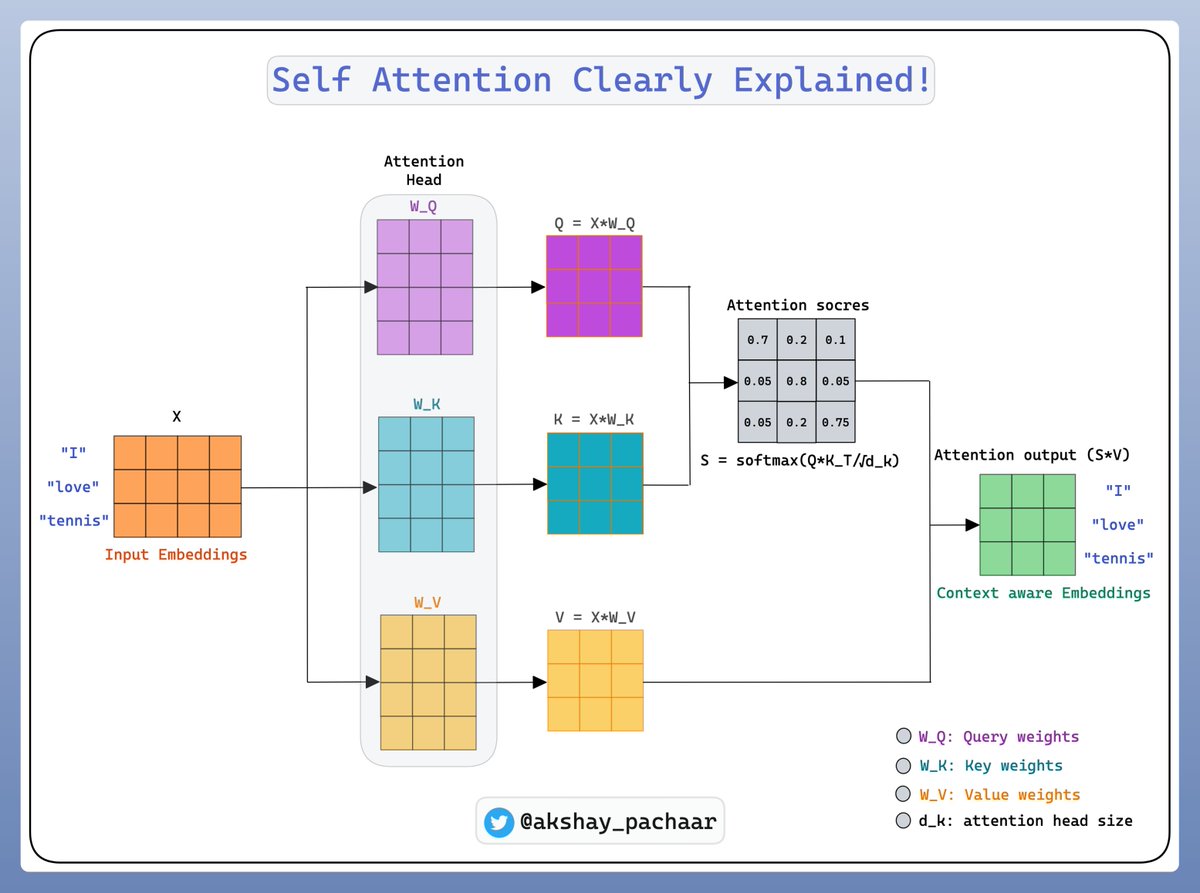
To understand how self-attention works we first need to understand 3 terms:
- Query Vector
- Key Vector
- Value Vector
These vectors are created by multiplying the input embedding by three weight matrices that are trainable.
Check this out 👇
- Query Vector
- Key Vector
- Value Vector
These vectors are created by multiplying the input embedding by three weight matrices that are trainable.
Check this out 👇

Self-attention allows models to learn long-range dependencies between different parts of a sequence.
After acquiring keys, queries, and values, we merge them to create a new set of context-aware embeddings.
Take a look at this!👇
After acquiring keys, queries, and values, we merge them to create a new set of context-aware embeddings.
Take a look at this!👇
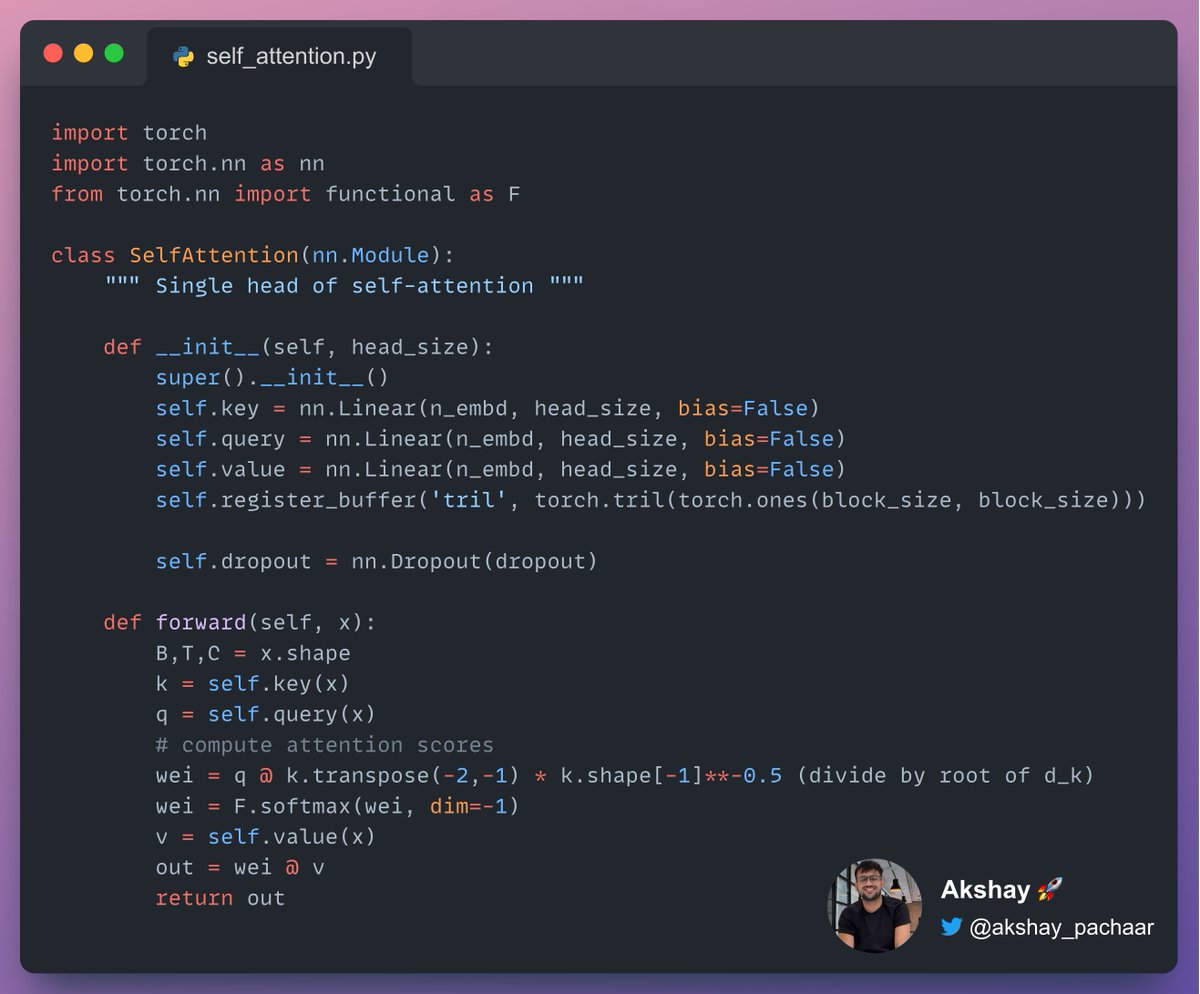
Implementing self-attention using PyTorch, doesn't get easier! 🚀
It's very intuitive! 💡
Check this out 👇
It's very intuitive! 💡
Check this out 👇
Understanding LLMs & LLMOps is going to be a high leverage skill in future!
@LightningAI provides state of the art tutorials on LLMs & LLMOps, I have personally learnt a lot from there.
Everything is free & Open-sourced 🔥
Check their blog 👇
lightning.ai
@LightningAI provides state of the art tutorials on LLMs & LLMOps, I have personally learnt a lot from there.
Everything is free & Open-sourced 🔥
Check their blog 👇
lightning.ai
That's a wrap!
If you interested in:
- Python 🐍
- Data Science 📈
- AI/ML 🤖
- LLMs 🧠
I'm sharing daily content over here, follow me → @akshay_pachaar if you haven't already!!
Cheers!! 🙂
If you interested in:
- Python 🐍
- Data Science 📈
- AI/ML 🤖
- LLMs 🧠
I'm sharing daily content over here, follow me → @akshay_pachaar if you haven't already!!
Cheers!! 🙂
Loading suggestions...