

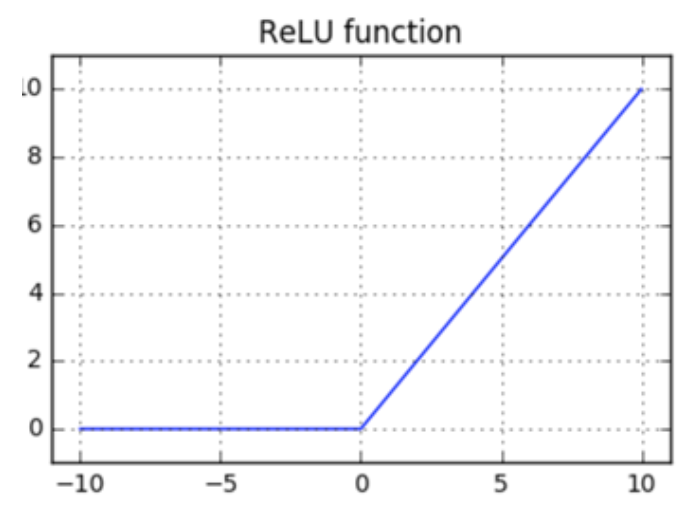
The most popular function in Machine Learning is probably this one:
f(x) = max(0, x)
The name of this function is "Rectified Linear Unit" or ReLU.
Unfortunately, most people think ReLU is both continuous and differentiable.
They are wrong.
f(x) = max(0, x)
The name of this function is "Rectified Linear Unit" or ReLU.
Unfortunately, most people think ReLU is both continuous and differentiable.
They are wrong.
Let's start by defining ReLU:
f(x) = max(0, x)
In English: if x <= 0, the function will return 0. Otherwise, the function will return x.
f(x) = max(0, x)
In English: if x <= 0, the function will return 0. Otherwise, the function will return x.
If you plot it, you'll notice no discontinuities in the function.
This should be enough to answer half of the original question: the ReLU function is continuous.
Let's now think about the differentiable part.
This should be enough to answer half of the original question: the ReLU function is continuous.
Let's now think about the differentiable part.

For a function to be differentiable, it must be continuous.
ReLU is continuous. That's good, but not enough.
Its derivative should also exist for every individual point.
Here is where things get interesting.
ReLU is continuous. That's good, but not enough.
Its derivative should also exist for every individual point.
Here is where things get interesting.
Look at ReLU's plot when x = 0.
That's where the function changes abruptly.
ReLU's derivative should exist at x = 0 for it to be differentiable.
To see whether the derivate exists, we can check that the left-hand and right-hand limits for the function exist and are the same.
That's where the function changes abruptly.
ReLU's derivative should exist at x = 0 for it to be differentiable.
To see whether the derivate exists, we can check that the left-hand and right-hand limits for the function exist and are the same.
So let's find out the left-hand limit.
In English: we want to compute the derivative using our formula when h approaches zero from the left.
At x = 0 and h < 0, we end up with the derivative being 0.
In English: we want to compute the derivative using our formula when h approaches zero from the left.
At x = 0 and h < 0, we end up with the derivative being 0.
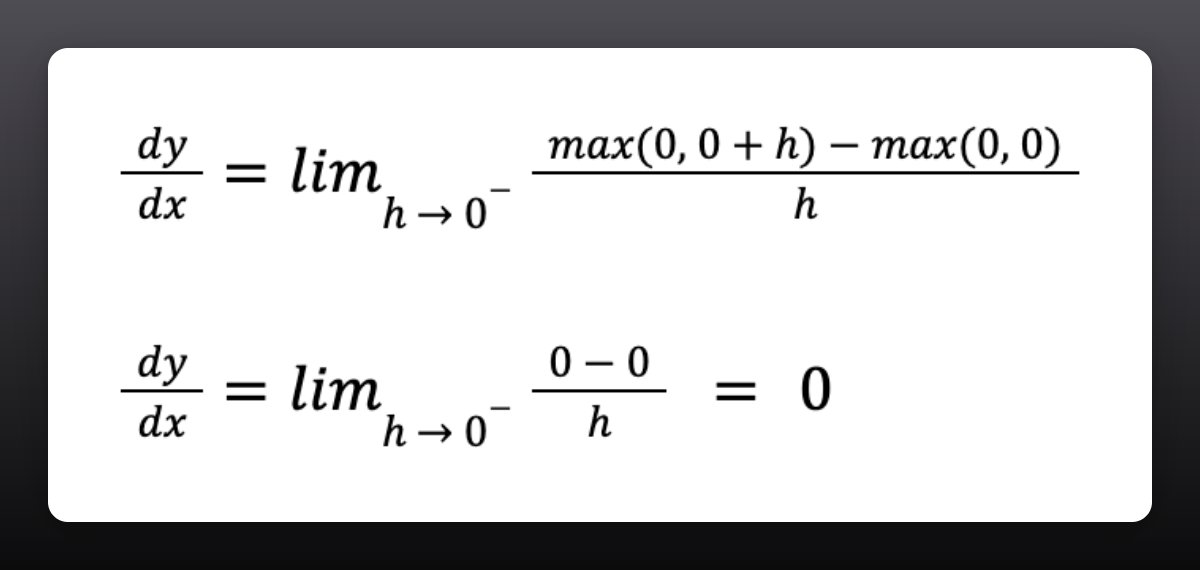
We can now do the same to compute the right-hand limit.
In this case, we want h to approach 0 from the right.
At x = 0 and h > 0, we will end up with the derivative being 1.
In this case, we want h to approach 0 from the right.
At x = 0 and h > 0, we will end up with the derivative being 1.
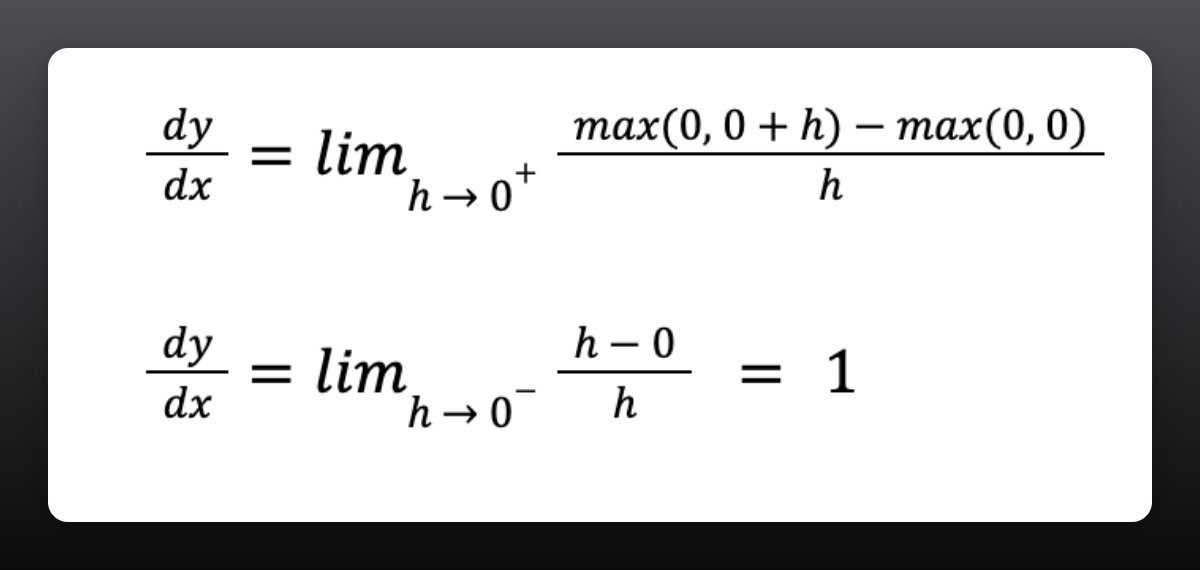
The left-hand limit is 0, and the right-hand limit is 1.
For the function's derivative to exist at x = 0, both the left-hand and right-hand limits should be the same.
This is not the case.
The derivative of ReLU doesn't exist at x = 0.
For the function's derivative to exist at x = 0, both the left-hand and right-hand limits should be the same.
This is not the case.
The derivative of ReLU doesn't exist at x = 0.
We now have the complete answer:
• ReLU is continuous
• ReLU is not differentiable
How can we use ReLU as an activation function when it's not differentiable?
• ReLU is continuous
• ReLU is not differentiable
How can we use ReLU as an activation function when it's not differentiable?
What happens is that we don't care that the derivative of ReLU is not defined when x = 0.
When this happens, we set the derivative to 0 (or any arbitrary value) and move on with our lives.
A nice hack.
This is the reason we can still use ReLU together with Gradient Descent.
When this happens, we set the derivative to 0 (or any arbitrary value) and move on with our lives.
A nice hack.
This is the reason we can still use ReLU together with Gradient Descent.
Loading suggestions...