

✅Feature Engineering explained in simple terms and how to use it ( with code).
A quick thread 🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #deeplearning
PC: ResearchGate
A quick thread 🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #deeplearning
PC: ResearchGate

1/ Imagine you want to teach a robot how to recognize different animals. To do that, you need to give it special eyes (cameras) and ears (microphones) so it can see and hear the animals. But the robot doesn't know what an animal looks or sounds like yet, so you have to teach it.
2/ You start by showing the robot pictures of animals and telling it what each animal is called. The robot looks at the pictures and tries to find patterns and features that are common to each animal.
3/ Then you give the robot audio recordings of different animal sounds. Again, it listens carefully and tries to find patterns and features that are unique to each animal. It might discover that dogs bark, while cats meow.
4/ Once the robot has learned these patterns and features, it can use them to recognize animals. If you show it a new picture or play a new sound, it will analyze the patterns and features it has learned and make a guess about what animal it is.
5/ Feature engineering is all about helping the robot (or a computer program) learn and understand important characteristics or features of things so it can make smart decisions or predictions. It's like giving the robot special senses to understand the world better!
6/ Feature engineering is the process of creating new features or modifying existing features in a dataset to improve the performance of a machine learning model. It involves selecting, transforming, and creating relevant features from the raw data.
7/ Feature engineering is done to extract the most useful information from the available data and present it in a way that helps the model make accurate predictions or classifications.
8/ Improve Model Performance: By engineering the features, you can provide the model with more relevant and discriminative information, leading to better predictions or classifications.
9/ Reduce Dimensionality: Feature engineering can help reduce the number of features in the dataset by combining or transforming them. This reduces the complexity of the model, improves computational efficiency, and mitigates the risk of overfitting.
10/ Capture Relevant Information: Feature engineering allows you to extract and include important information from the data that might not be directly available in the raw form. It helps the model understand the underlying patterns and relationships in the data.
11/ Handle Data Irregularities: Sometimes, the raw data may contain missing values, outliers, or other irregularities. Feature engineering techniques can help handle such issues, making the data more suitable for modeling.
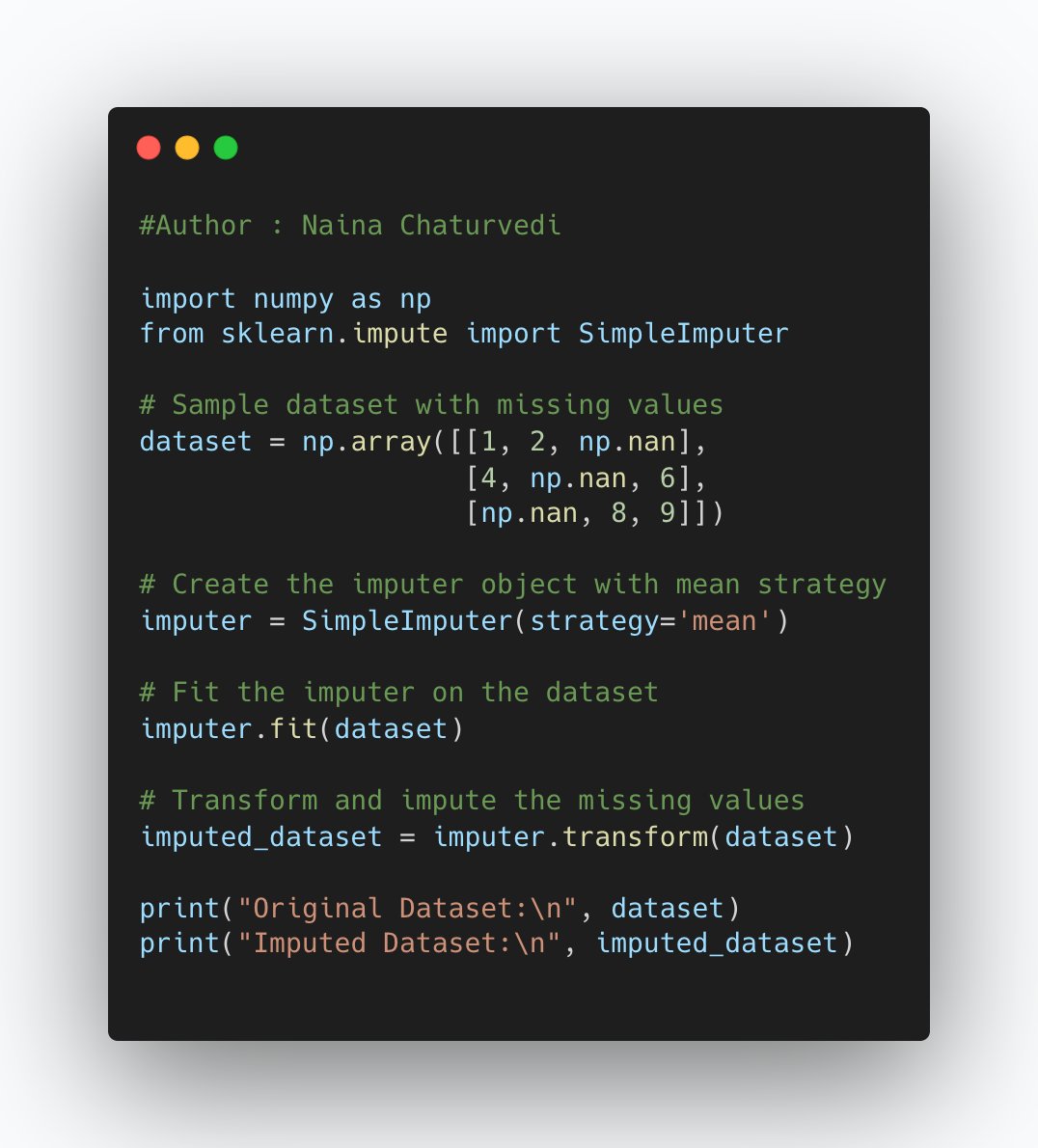
12/ Feature imputation is the process of filling in missing or null values in a dataset with estimated or substituted values. It is commonly performed to ensure that the dataset is complete and ready for analysis or machine learning tasks. Implementation --
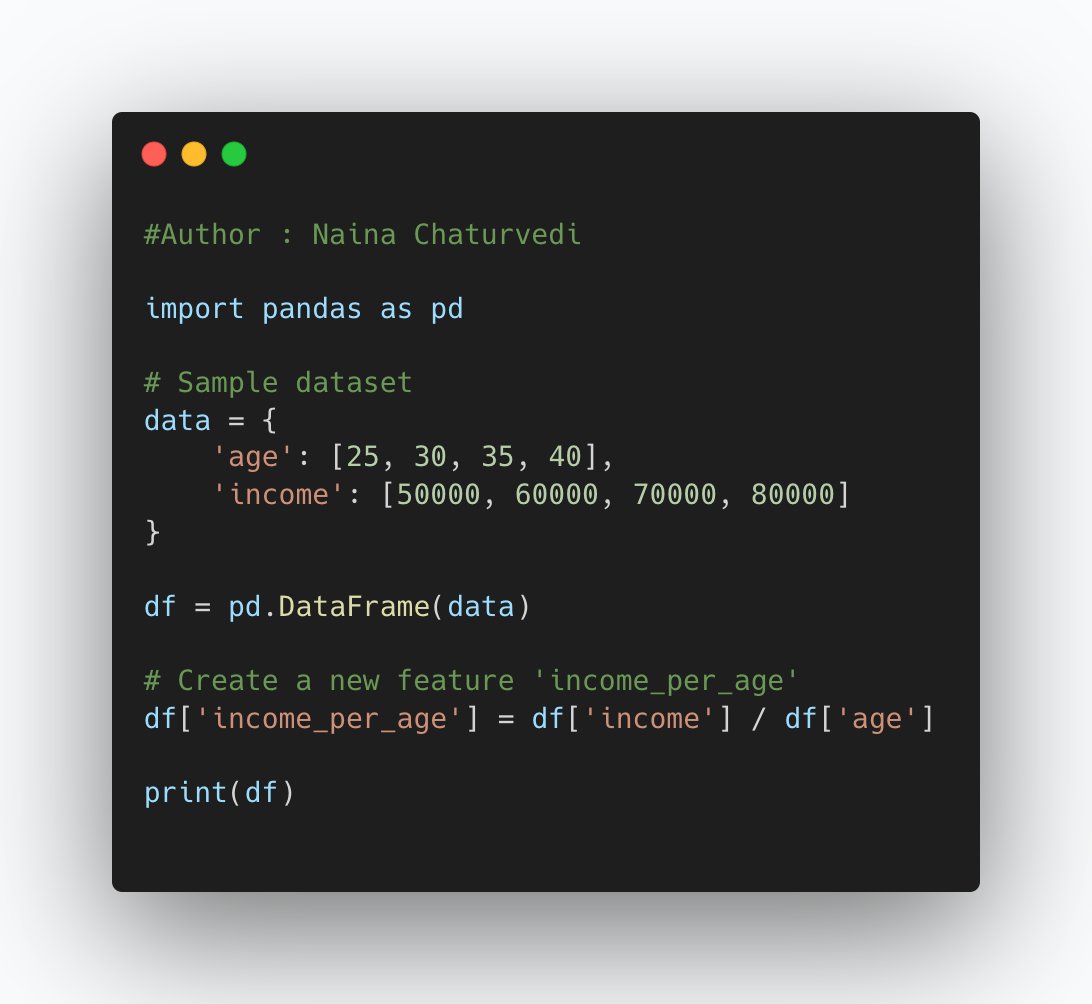
13/ Feature creation is the process of creating new features from existing ones or transforming existing features to extract more meaningful information for machine learning models. It involves statistical techniques, or mathematical transformations to derive new features.
14/ Feature transformation is the process of applying mathematical or statistical operations to transform the distribution or scale of features in a dataset. It is done to make the data more suitable for machine learning algorithms, improve model performance.

15/ Feature extraction is the process of automatically selecting/extracting the most relevant and informative features from raw data. It involves transforming the original data into a reduced set of features that capture the essential information necessary for a specific task.
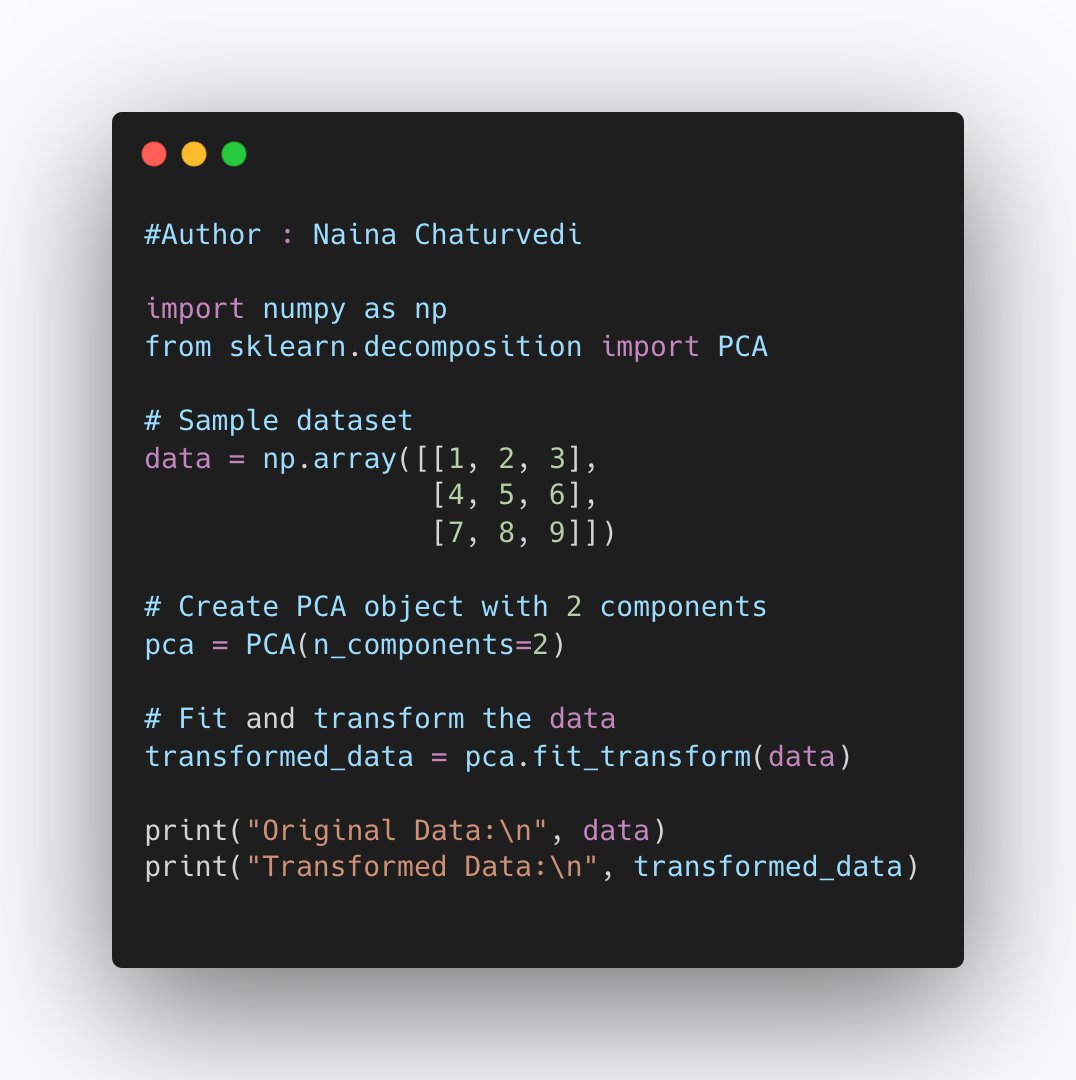
16/ Feature selection is process of selecting a subset of relevant features from a larger set of available features in a dataset. It aims to reduce the number of features while retaining the most informative ones, which can lead to improved model performance,reduced complexity.

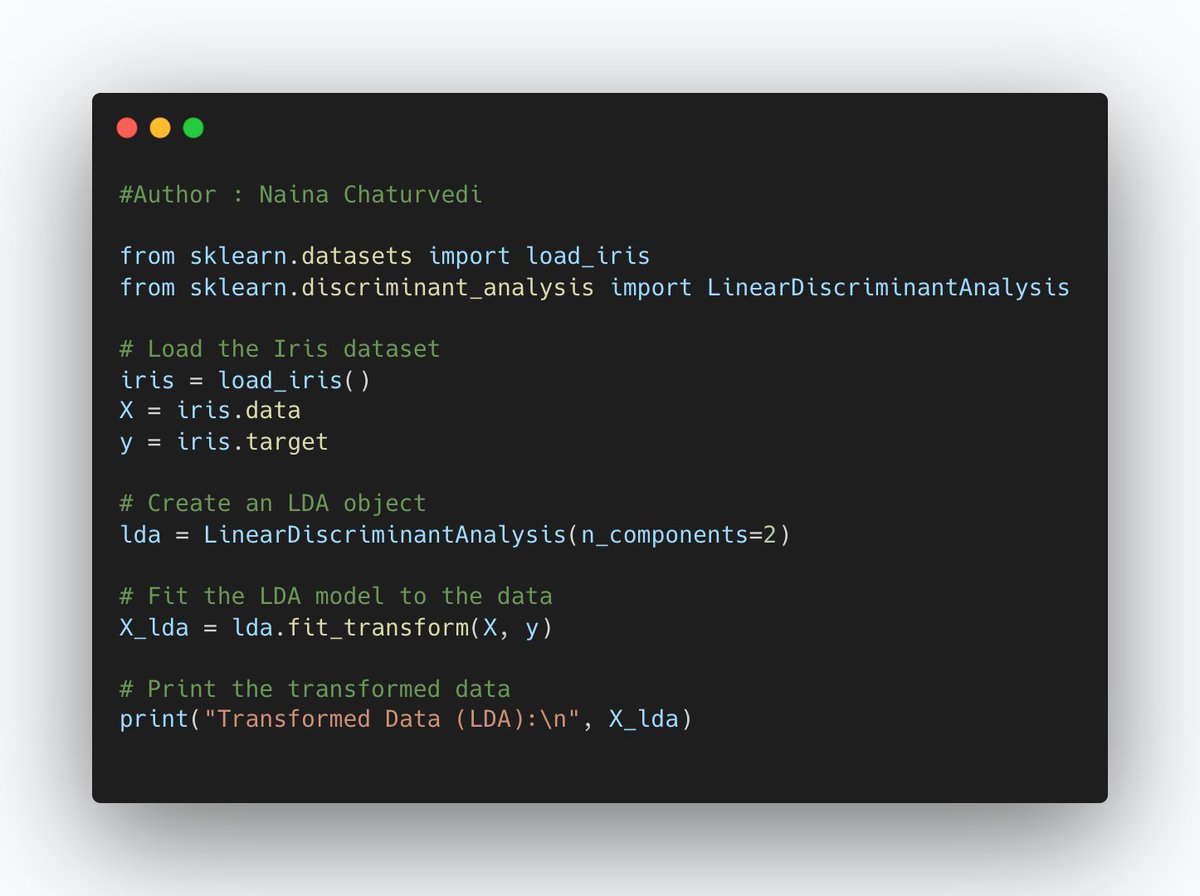
17/ Linear Discriminant Analysis is a technique used for both dimensionality reduction and classification. It aims to find a linear combination of features that maximizes the separation between classes while minimizing the variation within each class.
18/ t-SNE is a nonlinear technique for dimensionality reduction and visualization, effective for visualizing high-dimensional data. It focuses on preserving the local structure of data points, making it useful for exploring and clustering patterns in complex datasets.
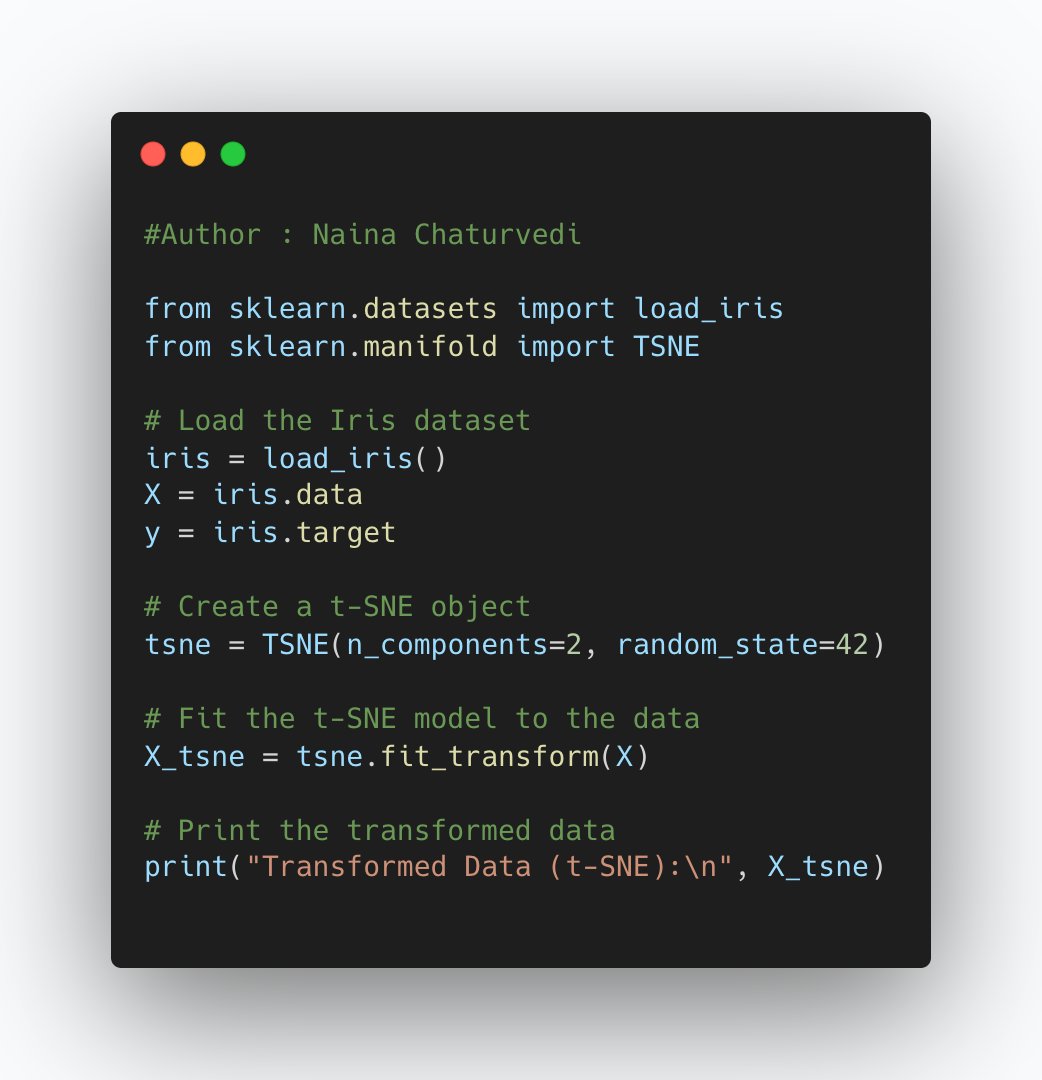
19/ Autoencoders are neural network models used for unsupervised learning and dimensionality reduction. They aim to reconstruct the input data from a compressed latent space representation, forcing the model to capture the most important features of the data.
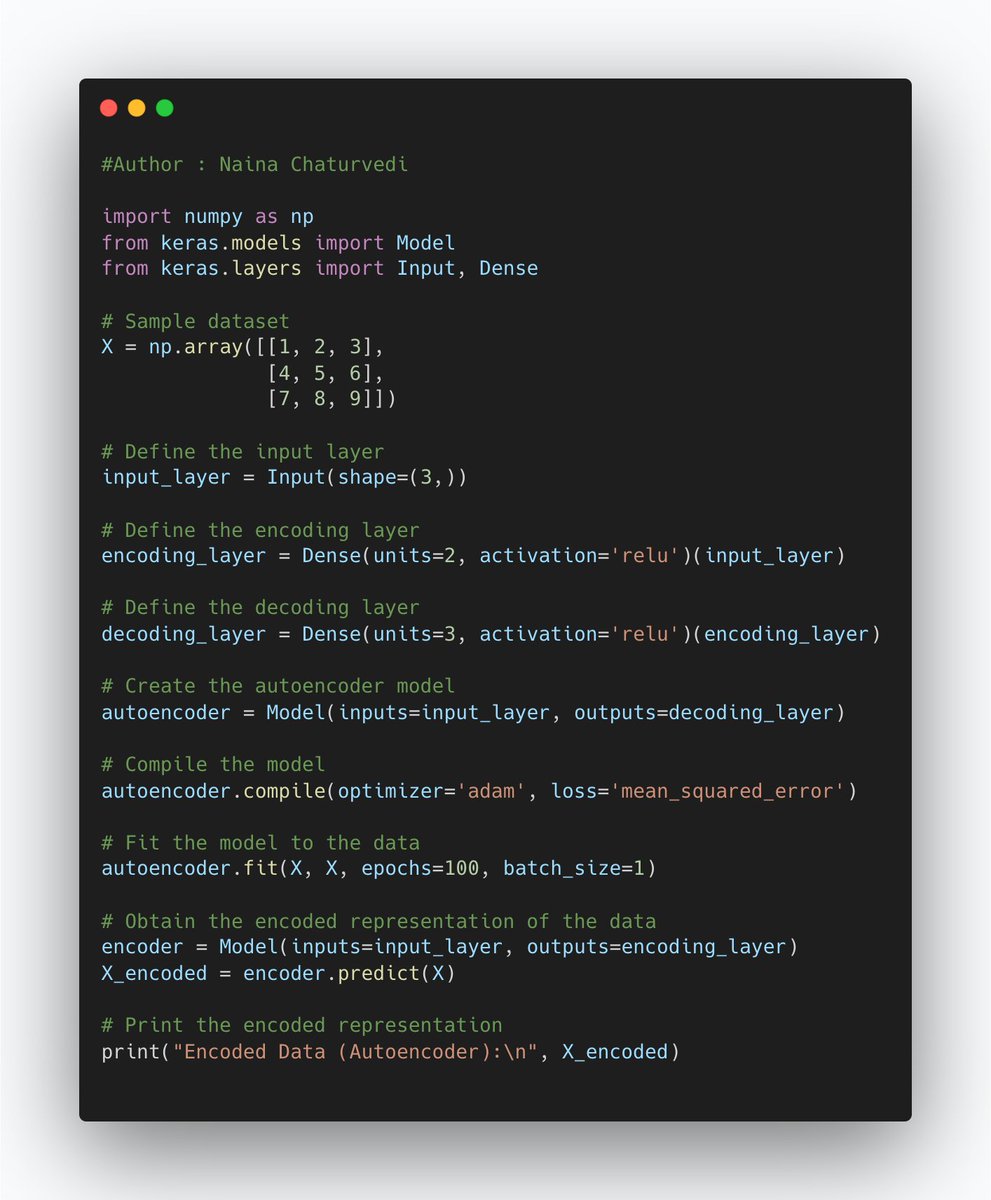
20/ Normalization is used in feature engineering to scale the values of numerical features within a specific range. It ensures that all feature values are on a similar scale, preventing certain features from dominating the model training process due to their larger magnitude.

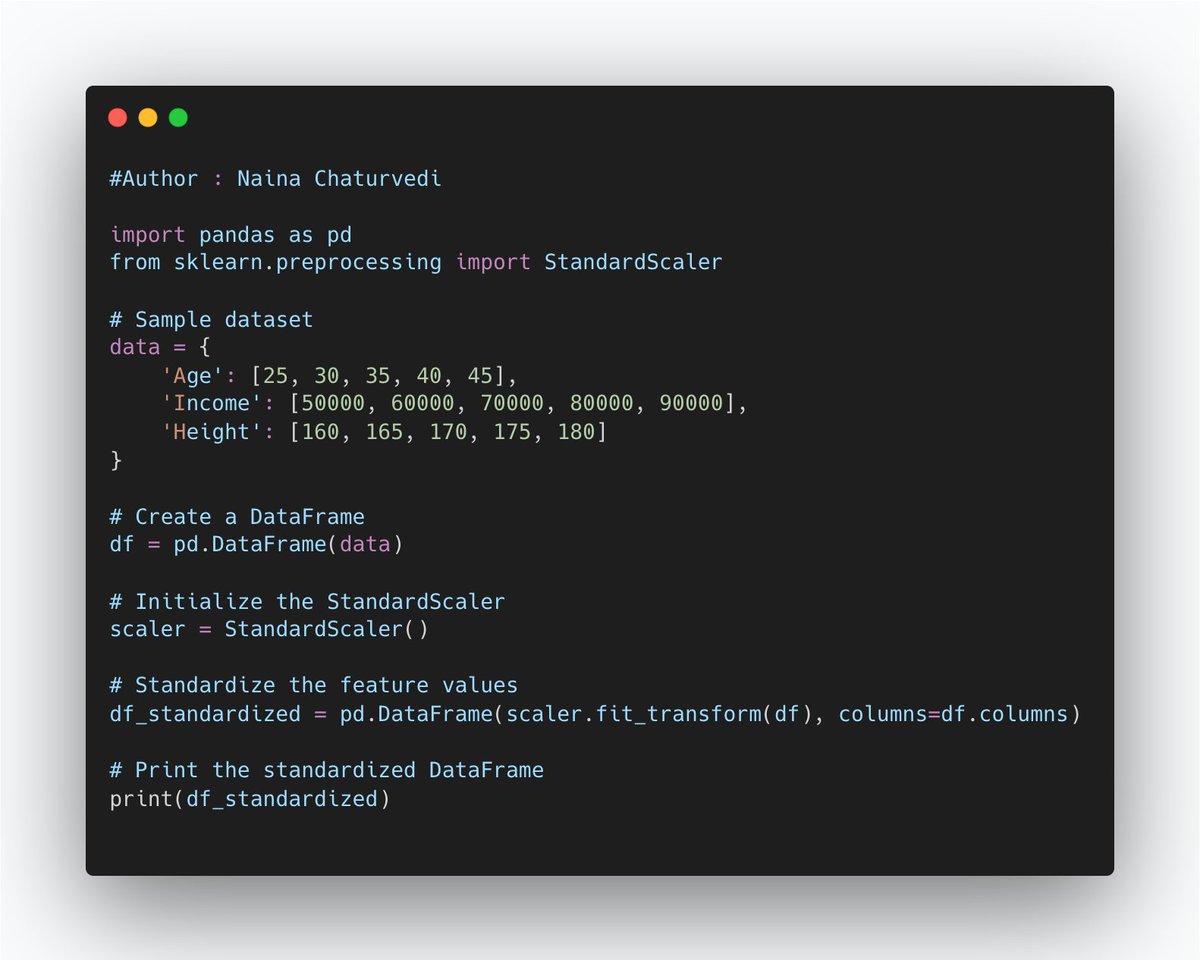
21/ Standardization is a technique used in feature engineering to transform numerical feature values such that they have zero mean and unit variance. It helps in bringing the feature values onto a standardized scale, making them easier to compare and interpret.
22/ Regression Imputation: Missing values in one feature can be estimated by building a regression model using other features as predictors. The model is trained on the instances where the target feature is not missing, and then used to predict the missing values.

naina0405.substack.com
Ignito | Naina Chaturvedi | Substack
Data Science, ML, AI and more... Click to read Ignito, by Naina Chaturvedi, a Substack publication w...

github.com/Coder-World04/…
GitHub - Coder-World04/Complete-Applied-Machine-Learning-with-Projects-Series: This repository contains everything you need to become proficient in Applied Machine Learning
This repository contains everything you need to become proficient in Applied Machine Learning - GitH...
Loading suggestions...