

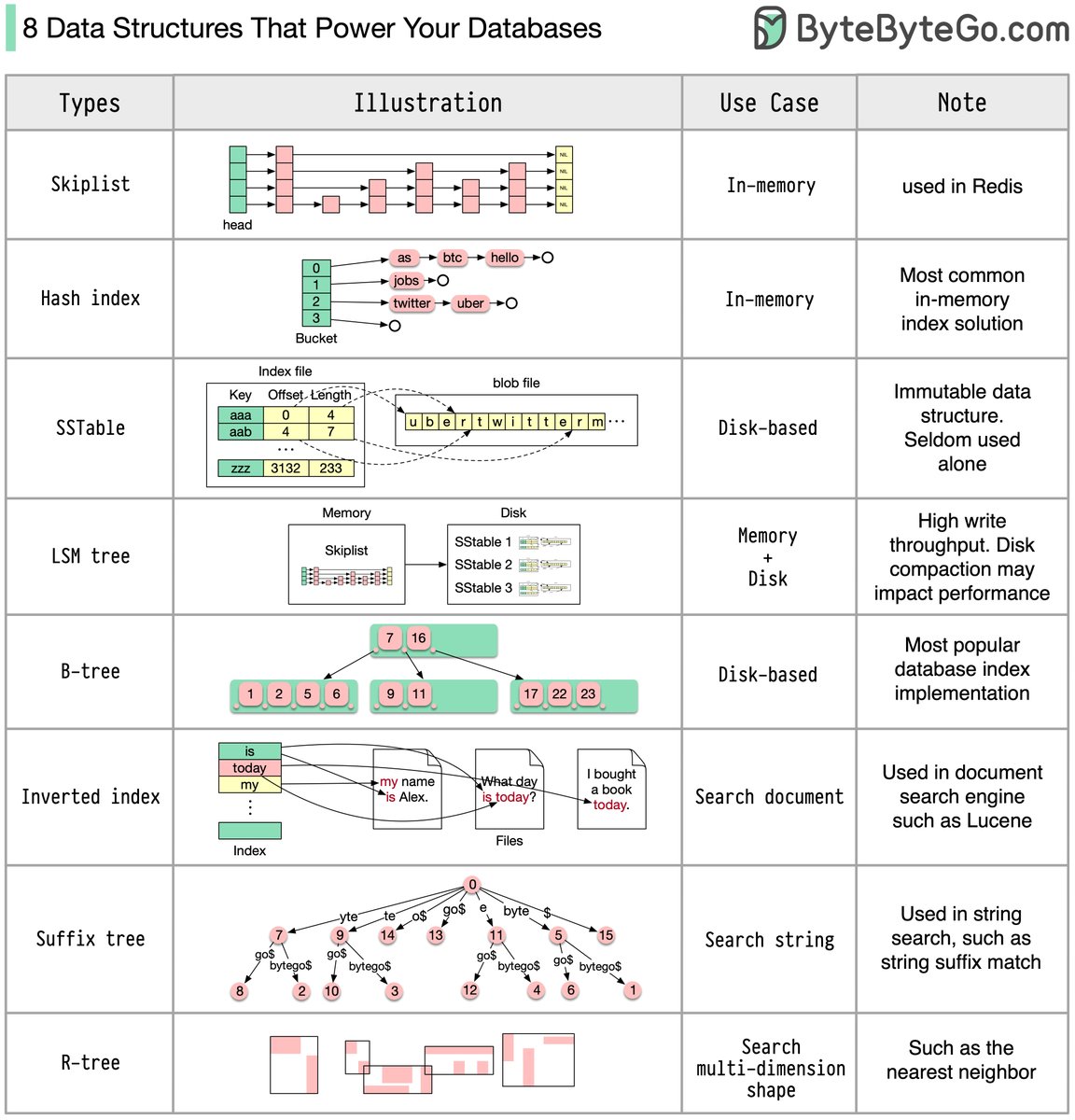
接)为简单起见我先讲它的简化版(应用于 #littlefs 文件系统),我们知道链表添加节点容易效率高,但按索引(序号/下标)查找节点时效率很低,需要从头扫一遍。skiplist在链表的基础上增加几条链,第2条每间隔1个节点连接,即节点0,2,4,6,8...第3条间隔3个即0,4,8,12,16...第4条间隔7个(续
接)即连接节点0,8,16,24,32...简而言之,第n条链就是每2^(n-1)个节点连接起来的链,形成类似图示那样的多层链表。当你需要查找某个节点时,从最高那条链开始寻找,遇到大于当前节点且小于下一个节点时就下降一条链寻找。比如寻找索引19的节点,路径是16,16,18,19,只需跳4次,从头顺序跳则要18次(续
接)上面是skiplist简化版,它不支持中间插入节点。而一般版本的原始链表是一个有序链表,可以中间插入节点。然后上层链间隔节点会疏一些,比如第2条每4节点,第3条每16节点,第4条每64节点。而且间隔数不是严格的固定值,而是按照预设的概率来抛硬币(coin-flip)觉得,比如设置25%概率来决定是否(续
接)在上一层链创建连接节点。删除中间节点时,并不需要重新构建上层链,虽然有时删除一些节点后会暂时变得紧密一些,但总体不影响。skiplist的实现非常简单,可以参考:geeksforgeeks.org
而 #lsm 树则可以看作是把原始(有序)链表简单地储存在磁盘上(叫做 #sstable),然后在内存构建(续
而 #lsm 树则可以看作是把原始(有序)链表简单地储存在磁盘上(叫做 #sstable),然后在内存构建(续

接)构建 skiplist 以记录每个 key 在文件的开始位置及 value 的长度。当然这个skiplist会更稀疏一些(也叫Sparse index)这样的一个组合形成一个 segment。一个 #nosql 数据库存在许多个segment,显然它们之间有可能存在重复的key,检索时取最新的版本即可。而最新添加的key-value则存放在内存中(续
接)内存中的一棵有序平衡树(称为memtable),同时为了防止数据丢失,新添加的kv对还以只增的方式写到一个日志文件里。当memtable比较大时,就会写入磁盘形成一个新的segment。nosql的主要实现思路大致如此,详细的可以参考:dev.to
表中的inverted index用于实现全文搜索(续
表中的inverted index用于实现全文搜索(续

接),方法是把一篇文章中的单词提取出来形成一个 “单词-出现次数”的map,然后多篇文章就形成“单词-文章编号” 的map,当用户以单词搜索时就会得出一组文章编号(搜索结果),如果多个关键字则取文章编号的交集。最后按照单词次数排序。suffix tree 则用于用户输入关键字时自动补完,这里就不介绍了。
Loading suggestions...