

Data preprocessing is a crucial step in the machine learning pipeline, ensuring that the dataset is ready for training.
One essential aspect of data preprocessing is ✨feature scaling✨, which involves adjusting the range and distribution of the data.
🧵 👇
One essential aspect of data preprocessing is ✨feature scaling✨, which involves adjusting the range and distribution of the data.
🧵 👇
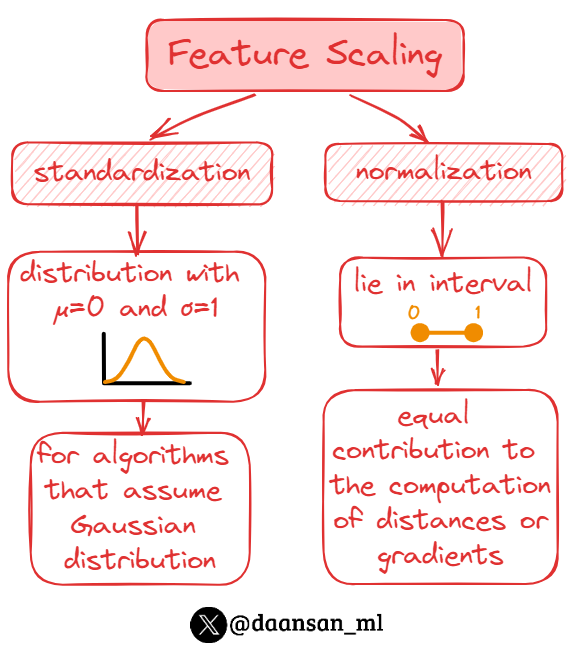
Feature scaling techniques, such as:
🔹 normalization
🔹 standardization
ensure that each attribute contributes equally to the algorithm's performance, thereby enhancing the predictive model's accuracy and efficiency.
🔹 normalization
🔹 standardization
ensure that each attribute contributes equally to the algorithm's performance, thereby enhancing the predictive model's accuracy and efficiency.
Both normalization and standardization aim to re-scale features, but they do so in different ways and are suitable for different types of data and machine learning algorithms.
1️⃣ Normalization:
It is a technique used to scale the features to a similar range. The goal is to transform them to lie in a certain interval, usually [0,1], making it easier for algorithms to interpret them → equal contribution to the computation of distances or gradients.
It is a technique used to scale the features to a similar range. The goal is to transform them to lie in a certain interval, usually [0,1], making it easier for algorithms to interpret them → equal contribution to the computation of distances or gradients.
👉 This is why it is especially important for distance-based algorithms like KNN, or when your features have different units or vastly different scales.
2️⃣ Standardization:
Standardization, unlike normalization, transforms the features in a way that the resulting distribution has a mean of 0 and a standard deviation of 1. It doesn't bound values to a specific range.
Standardization, unlike normalization, transforms the features in a way that the resulting distribution has a mean of 0 and a standard deviation of 1. It doesn't bound values to a specific range.
👉 This is especially useful for algorithms that assume the input variables to have a Gaussian distribution.
You should also join our newsletter, DSBoost.
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev

Loading suggestions...