

✅ Training and Evaluation in ML - Explained in simple terms.
A quick thread 🧵👇🏻
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
A quick thread 🧵👇🏻
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate

1/ Training is the process of teaching a machine learning model to make predictions or decisions by learning patterns and relationships from a labeled dataset. During training, the model adjusts its internal parameters based on the input data and associated ground truth labels.

2/ How it works: In supervised learning, a model starts with initial parameter values and makes predictions on the training data. It computes a loss or error by comparing its predictions to the true labels.
3/ Then, optimization techniques (e.g., gradient descent) are used to update the model's parameters iteratively, minimizing the loss and improving its predictive capabilities.
4/ When to use it: Training is used when you have labeled data and want to build a predictive model that can generalize to make accurate predictions on new, unseen data. It's a crucial step in creating ML models for various tasks, including classification, regression.
5/ Why to use it: Training allows a model to learn from historical data and capture underlying patterns and relationships. It helps the model generalize its knowledge to make predictions on unseen data, which is the primary goal of machine learning.
6/ Evaluation is the process of assessing the performance of a trained machine learning model on a separate dataset that it has not seen during training. It measures how well the model generalizes to make predictions on new, unseen data and quantifies its predictive accuracy.
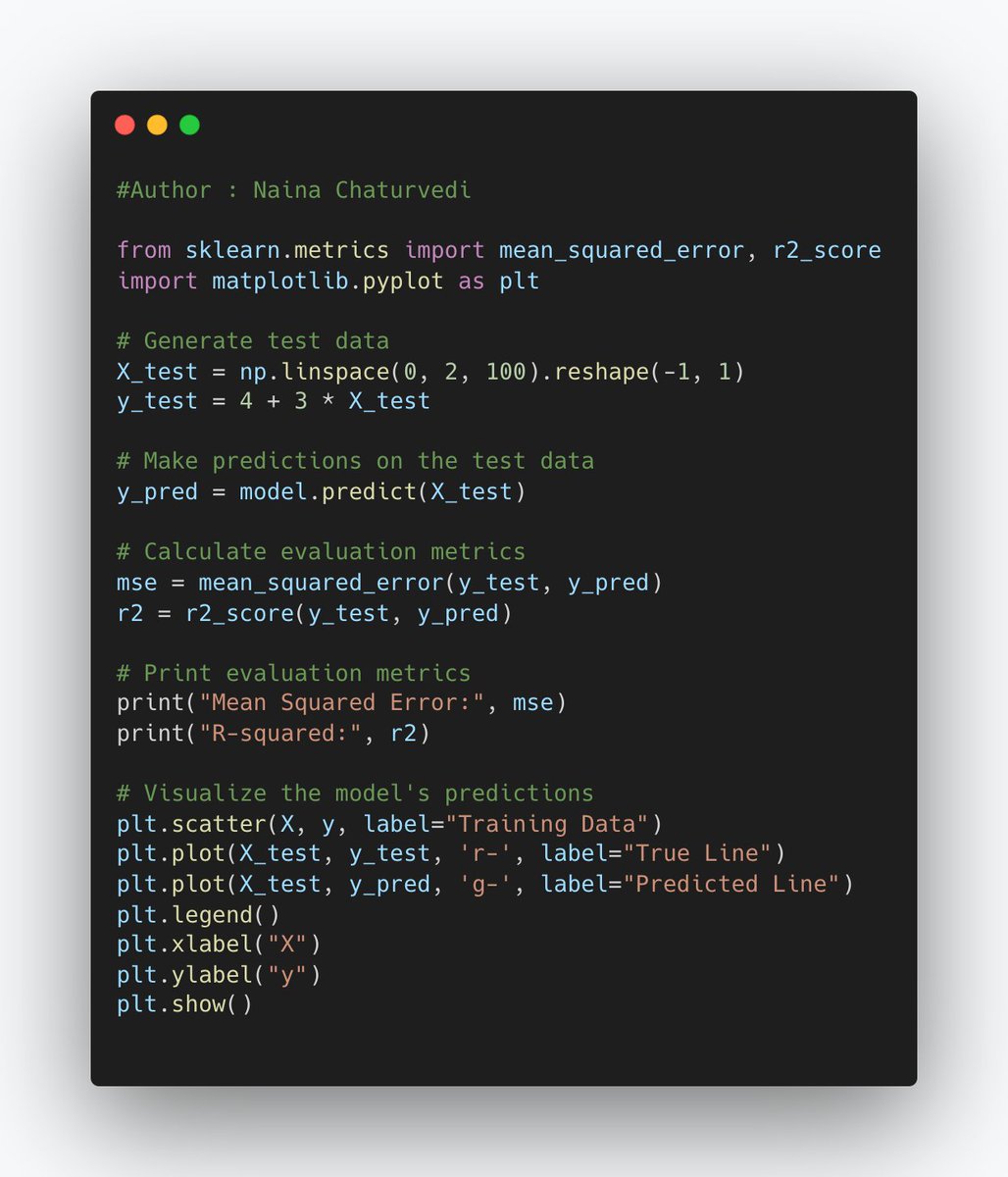
7/ Trained model is applied to evaluation dataset, and its predictions are compared to true labels or target values in that dataset. Evaluation metrics, such as accuracy, precision, recall, F1-score, mean squared error (MSE), etc., are used to measure the model's performance.
8/ When to use it: Evaluation is used after model training to determine how well the model is likely to perform in real-world scenarios. It helps assess whether the model meets the desired level of accuracy and whether it is suitable for deployment.
9/ Why to use it: It provides an objective measure of a model's performance, allowing you to assess its strengths and weaknesses. It helps identify whether the model is overfitting or underfitting. It also guides model selection and hyperparameter tuning to improve performance.
10/ Data splitting is a fundamental step in machine learning that involves dividing a dataset into three distinct subsets: the training set, the validation set, and the test set.
11/The training set is the portion of the dataset used to train the machine learning model. It consists of input data and corresponding target labels or ground truth.

12/Importance: The training set is used to teach the model to recognize patterns and relationships in the data. During training, the model's parameters are adjusted to minimize the prediction error on the training data, enabling it to capture underlying patterns.
13/ The validation set is a separate portion of the dataset used to tune model hyperparameters and monitor its performance during training. It is not used for training the model's parameters.

14/ Importance: The validation set helps in selecting the best model architecture, hyperparameters, and preventing overfitting. By evaluating the model on the validation set, you can make adjustments to the model and hyperparameters as needed.
15/The test set is a completely independent portion of the dataset that is not seen by the model during training or hyperparameter tuning. It is reserved for the final evaluation of the model's performance.
16/ Importance: The test set provides an unbiased assessment of the model's generalization performance on unseen data. It simulates real-world scenarios where the model encounters new, unobserved examples.
17/ Data normalization is the process of scaling the numerical features in your dataset to a standard range. Normalization ensures that different features are on a similar scale, preventing some features from dominating others during model training.

18/ Importance: Normalization helps improve the training process and convergence of many machine learning algorithms, especially those sensitive to feature scaling, such as gradient-based optimization methods.
19/ Handling missing values is essential because many machine learning algorithms cannot work with data containing missing values. Common strategies include removing rows with missing values, imputing missing values with a fixed value or using advanced imputation techniques.

20/ Importance: Addressing missing values ensures that your model can make predictions on all data points without issues and prevents biases in the model.
21/ One-hot encoding is a technique for handling categorical variables by converting them into binary vectors. Each category becomes a binary feature (0 or 1) indicating the presence or absence of that category.

22/ Importance: Machine learning models typically work with numerical data, so categorical variables must be converted to a format that the models can understand. One-hot encoding prevents ordinal relationships between categories.
23/ Feature creation involves generating new features from existing data to provide additional information that may be useful for the model. This can include mathematical operations, aggregations, or transformations of existing features.

24/ Importance: Creating new features can help the model capture complex relationships in the data that may not be apparent with the original features.
Loading suggestions...