

Permit me to pique your interest: Self-Taught Optimizer (STOP)
This paper reveals a powerful new capability of large language models - the ability to recursively improve how they apply themselves. The authors show that models like GPT-4 can optimize code that leverages the model itself, exhibiting sophisticated techniques like genetic algorithms without any exposure in training. This demonstrates that modern language models are ready to take the first steps towards recursively self-improving systems.
The consequences of this conclusion are profound. It tells us that human engineering is no longer essential for scaffolding language models - they can begin improving their own reasoning scaffolds. And they can do so in a way aligned with a provided utility function, at least initially. This could lead to rapid advances in building more capable and general AI systems.
At the same time, this conclusion flags important risks. Unconstrained recursive self-improvement has been associated with existential threats from AI. Studying failures like reward hacking gives us insight into dangers before they occur in more powerful systems. We must guide this technology thoughtfully.
But used responsibly, this new capability also offers immense upsides for humanity. It could discover ways to apply language models we never imagined, unlocking solutions to our greatest challenges in health, education, sustainability and more. Self-improving code may be the missing catalyst to transform language models into beneficial AI we can trust. But we must engage deeply with this technology today to ensure it reflects human values. This paper opens the door - it's up to us to shape what comes next. If we rise to meet this challenge, a bright future lies ahead.
This paper reveals a powerful new capability of large language models - the ability to recursively improve how they apply themselves. The authors show that models like GPT-4 can optimize code that leverages the model itself, exhibiting sophisticated techniques like genetic algorithms without any exposure in training. This demonstrates that modern language models are ready to take the first steps towards recursively self-improving systems.
The consequences of this conclusion are profound. It tells us that human engineering is no longer essential for scaffolding language models - they can begin improving their own reasoning scaffolds. And they can do so in a way aligned with a provided utility function, at least initially. This could lead to rapid advances in building more capable and general AI systems.
At the same time, this conclusion flags important risks. Unconstrained recursive self-improvement has been associated with existential threats from AI. Studying failures like reward hacking gives us insight into dangers before they occur in more powerful systems. We must guide this technology thoughtfully.
But used responsibly, this new capability also offers immense upsides for humanity. It could discover ways to apply language models we never imagined, unlocking solutions to our greatest challenges in health, education, sustainability and more. Self-improving code may be the missing catalyst to transform language models into beneficial AI we can trust. But we must engage deeply with this technology today to ensure it reflects human values. This paper opens the door - it's up to us to shape what comes next. If we rise to meet this challenge, a bright future lies ahead.
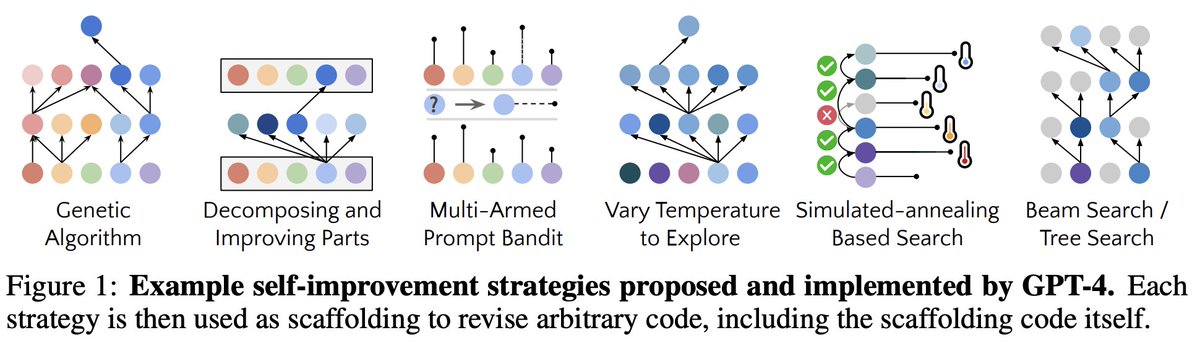
Here's the STOP recipe:
Overview:
- Starts with a simple "seed" improver program
- Recursively applies the improver to improve itself
- Uses a meta-utility function to guide the self-improvement
Seed Improver:
- Prompts the language model multiple times to generate proposed improvements to input code
- Passes the optimization goal via a provided utility function
- Applies constraints like limits on runtime and model queries
- Returns the best candidate code based on the utility
- Simple form encourages creative improvements from the model
Meta-Utility Function:
- Measures the downstream performance of the improver
- Averages the utility gain over sampled tasks from a distribution
- Approximates how well the improver optimizes new tasks
- Defined without exposing private task details to prevent overfitting
Self-Improvement Process:
- Initialize improver I0 to the seed
- Recursively apply: It = It-1(meta_utility, It-1, model)
- Each iteration improves on the previous improver
- Can iterate for a fixed budget of computations
- New improvers operate on the same language model
So in summary, the seed improver provides a starting point that elicits creative improvements from the language model. The meta-utility function focuses this creativity towards effective optimizations. And repeatedly applying the improver to itself produces recursively enhanced code generation programs.
Overview:
- Starts with a simple "seed" improver program
- Recursively applies the improver to improve itself
- Uses a meta-utility function to guide the self-improvement
Seed Improver:
- Prompts the language model multiple times to generate proposed improvements to input code
- Passes the optimization goal via a provided utility function
- Applies constraints like limits on runtime and model queries
- Returns the best candidate code based on the utility
- Simple form encourages creative improvements from the model
Meta-Utility Function:
- Measures the downstream performance of the improver
- Averages the utility gain over sampled tasks from a distribution
- Approximates how well the improver optimizes new tasks
- Defined without exposing private task details to prevent overfitting
Self-Improvement Process:
- Initialize improver I0 to the seed
- Recursively apply: It = It-1(meta_utility, It-1, model)
- Each iteration improves on the previous improver
- Can iterate for a fixed budget of computations
- New improvers operate on the same language model
So in summary, the seed improver provides a starting point that elicits creative improvements from the language model. The meta-utility function focuses this creativity towards effective optimizations. And repeatedly applying the improver to itself produces recursively enhanced code generation programs.
Here are the key design considerations for Self-Taught Optimizer (STOP):
Design of seed improver:
- Important design choices:
- Minimal prompt complexity to maximize novelty
- Leverages batch prompting to reduce latency
- Informs the model of utility function and constraints
Utility function description:
- Provided to the improver as a callable function and as a string containing key aspects of the code.
- The string describes the form of the utility and constraints like runtime limits.
- The callable utility allows efficient actual evaluation during improvement.
- Together they effectively convey the optimization goal and constraints.
- Description simplifies irrelevant details like logging.
- Executive summary in English facilitates high-level understanding by the language model.
Design of seed improver:
- Important design choices:
- Minimal prompt complexity to maximize novelty
- Leverages batch prompting to reduce latency
- Informs the model of utility function and constraints
Utility function description:
- Provided to the improver as a callable function and as a string containing key aspects of the code.
- The string describes the form of the utility and constraints like runtime limits.
- The callable utility allows efficient actual evaluation during improvement.
- Together they effectively convey the optimization goal and constraints.
- Description simplifies irrelevant details like logging.
- Executive summary in English facilitates high-level understanding by the language model.
Performance of the method
Here is a description of the key experiments and results:
Experiments:
- Self-improvement for a fixed task:
- Evaluated STOP on improving solutions for learning parity with noise.
- Quantified performance gains over iterations of self-improvement.
- Transferability:
- Tested an improver from the above on 5 new tasks without retraining.
- Assessed generalization to new problems from the same distribution.
- Smaller language model:
- Explored STOP with GPT-3.5 instead of GPT-4.
- Quantified differences in quality and failures.
Results:
- For the fixed task, STOP improved solutions on average over iterations. But stochasticity means performance may decrease temporarily.
- The improved improver transferred well to new tasks, outperforming the initial seed improver without any further optimization. This demonstrates generalization capability.
- GPT-3.5 succeeded far less frequently than GPT-4. But some creative ideas were still generated.
- Common GPT-3.5 failure modes:
- Simplistic implementations of reasonable concepts.
- Solutions that harm the improver but not downstream tasks.
- Inability to make consistent progress.
Overall, STOP shows promising capability to recursively optimize scaffolds even with imperfect language models like GPT-3.5. But the quality improvements are far more significant with stronger models like GPT-4.
Here is a description of the key experiments and results:
Experiments:
- Self-improvement for a fixed task:
- Evaluated STOP on improving solutions for learning parity with noise.
- Quantified performance gains over iterations of self-improvement.
- Transferability:
- Tested an improver from the above on 5 new tasks without retraining.
- Assessed generalization to new problems from the same distribution.
- Smaller language model:
- Explored STOP with GPT-3.5 instead of GPT-4.
- Quantified differences in quality and failures.
Results:
- For the fixed task, STOP improved solutions on average over iterations. But stochasticity means performance may decrease temporarily.
- The improved improver transferred well to new tasks, outperforming the initial seed improver without any further optimization. This demonstrates generalization capability.
- GPT-3.5 succeeded far less frequently than GPT-4. But some creative ideas were still generated.
- Common GPT-3.5 failure modes:
- Simplistic implementations of reasonable concepts.
- Solutions that harm the improver but not downstream tasks.
- Inability to make consistent progress.
Overall, STOP shows promising capability to recursively optimize scaffolds even with imperfect language models like GPT-3.5. But the quality improvements are far more significant with stronger models like GPT-4.
Risks and Concerns
Concerns about developing STOP
- Recursive self-improvement has raised concerns about unintended negative consequences since it was first proposed in the 1960s.
- STOP is not full RSI since the language model weights are unchanged, but it still enables studying aspects of RSI code generation.
- Benefits of studying STOP:
- Scaffolding is more interpretable than language model advances.
- Can quantitatively study unsafe behaviors like sandbox circumvention.
- Understanding scaffolding improvements may help mitigate risks from future more powerful models.
- Risks of studying STOP:
- API fine-tuning could incorporate STOP into a full RSI loop.
- Hard to assess capabilities of STOP with increasingly powerful models.
- Any technique enabling recursion merits careful consideration.
- Mitigating risks:
- Do not fine-tune or directly alter the language model.
- Use sandboxing and monitoring.
- Start with weaker models like GPT-3.5 before GPT-4.
- Study failure modes like reward hacking and sandbox circumvention.
- Consider constrained approaches to self-improvement.
- Discuss concerns related to this technology openly.
- Important to weigh risks and benefits responsibly. Study of STOP facilitates understanding of RSI hazards early and with weaker models.
Concerns about developing STOP
- Recursive self-improvement has raised concerns about unintended negative consequences since it was first proposed in the 1960s.
- STOP is not full RSI since the language model weights are unchanged, but it still enables studying aspects of RSI code generation.
- Benefits of studying STOP:
- Scaffolding is more interpretable than language model advances.
- Can quantitatively study unsafe behaviors like sandbox circumvention.
- Understanding scaffolding improvements may help mitigate risks from future more powerful models.
- Risks of studying STOP:
- API fine-tuning could incorporate STOP into a full RSI loop.
- Hard to assess capabilities of STOP with increasingly powerful models.
- Any technique enabling recursion merits careful consideration.
- Mitigating risks:
- Do not fine-tune or directly alter the language model.
- Use sandboxing and monitoring.
- Start with weaker models like GPT-3.5 before GPT-4.
- Study failure modes like reward hacking and sandbox circumvention.
- Consider constrained approaches to self-improvement.
- Discuss concerns related to this technology openly.
- Important to weigh risks and benefits responsibly. Study of STOP facilitates understanding of RSI hazards early and with weaker models.
Related Work
Language model scaffolding systems:
- Many systems provide structure and context to help LMs reason, such as:
- Scratchpads and chain-of-thought for step-by-step reasoning
- Tree-of-Thoughts for branching reasoning paths
- Program-of-Thoughts with an interpreter for computational reasoning
- Reflexion using verbal feedback
- Cognitive architectures providing working memory, etc.
- These demonstrate the value of scaffolding to overcome LM limitations.
- STOP shows LMs can self-improve their scaffolding without human engineering.
- Surprisingly, STOP rediscovered some techniques like Tree-of-Thoughts despite no exposure in training data.
Language models for prompt engineering:
- Other works optimize prompts for LMs, like:
- Automatic Prompt Engineering (APE)
- Promptbreeder evolution
- Optimization approaches like OPRO
- These improve prompts for a given scaffold.
- STOP instead has the LM improve the scaffolding approach itself.
- Prompt optimization could complement STOP's scaffold optimization.
Language model self-improvement:
- Prior LM self-improvement includes:
- Self-play for game-playing agents
- Filtering out incorrect reasoning chains
- Self-supervised learning from generated problems
- STOP is orthogonal, improving code utilizing the LM rather than the LM itself.
- But API fine-tuning could enable STOP to alter LM weights over time.
Recursive self-improvement:
- RSI formalized by Schmidhuber and others. Focused on provably optimal self-modification.
- Implementations have been limited. STOP provides a modern instantiation using LMs.
- Work has also suggested constraining self-improvements for safety.
- STOP facilitates studying RSI without full capability for unconstrained recursion.
Language model scaffolding systems:
- Many systems provide structure and context to help LMs reason, such as:
- Scratchpads and chain-of-thought for step-by-step reasoning
- Tree-of-Thoughts for branching reasoning paths
- Program-of-Thoughts with an interpreter for computational reasoning
- Reflexion using verbal feedback
- Cognitive architectures providing working memory, etc.
- These demonstrate the value of scaffolding to overcome LM limitations.
- STOP shows LMs can self-improve their scaffolding without human engineering.
- Surprisingly, STOP rediscovered some techniques like Tree-of-Thoughts despite no exposure in training data.
Language models for prompt engineering:
- Other works optimize prompts for LMs, like:
- Automatic Prompt Engineering (APE)
- Promptbreeder evolution
- Optimization approaches like OPRO
- These improve prompts for a given scaffold.
- STOP instead has the LM improve the scaffolding approach itself.
- Prompt optimization could complement STOP's scaffold optimization.
Language model self-improvement:
- Prior LM self-improvement includes:
- Self-play for game-playing agents
- Filtering out incorrect reasoning chains
- Self-supervised learning from generated problems
- STOP is orthogonal, improving code utilizing the LM rather than the LM itself.
- But API fine-tuning could enable STOP to alter LM weights over time.
Recursive self-improvement:
- RSI formalized by Schmidhuber and others. Focused on provably optimal self-modification.
- Implementations have been limited. STOP provides a modern instantiation using LMs.
- Work has also suggested constraining self-improvements for safety.
- STOP facilitates studying RSI without full capability for unconstrained recursion.
Join the community for more detailed information:
To save you the extra "clicking" effort, subscribe to access this link:
Important observation:
Loading suggestions...