

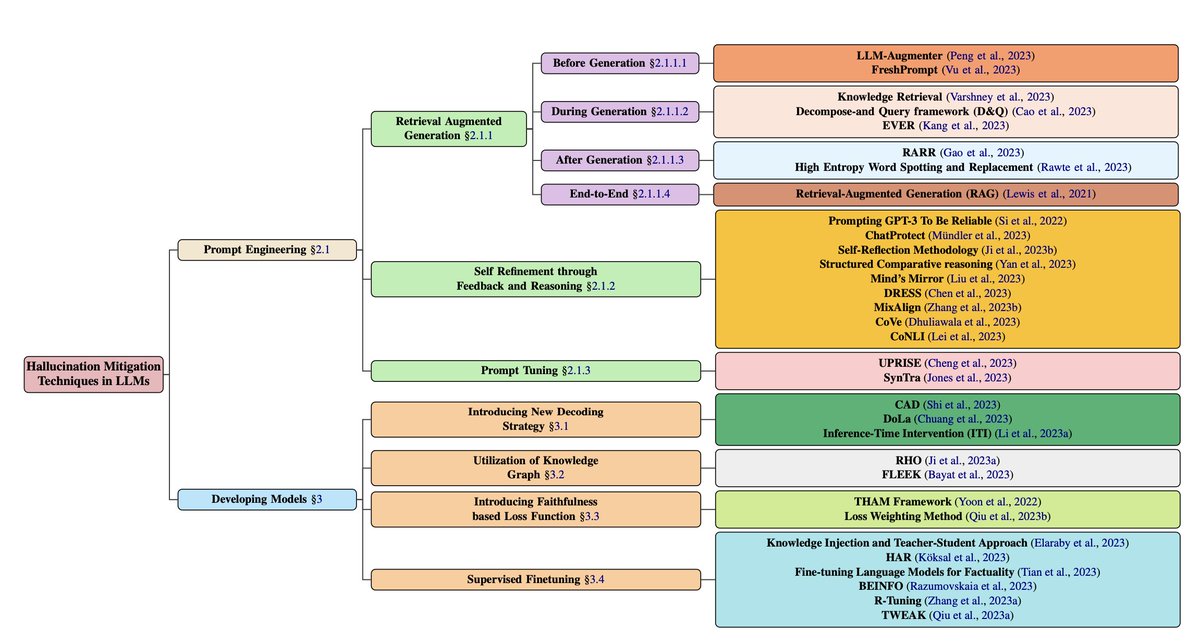
1/n An ontology for hallucination mitigation techniques in Large Language Models (LLMs).
Prompt Engineering category
A. Retrieval Augmented Generation (RAG)
- Before Generation: Strategies where information retrieval happens before text generation, e.g. LLM-Augmenter
- During Generation: Retrieval at sentence level generation, e.g. Knowledge Retrieval, D&Q Framework
- After Generation: Retrieval after full text generation, e.g. RARR
- End-to-End: Integrated retrieval and generation models, e.g. Original RAG model
B. Self-Refinement through Feedback and Reasoning
- Iterative refinement of outputs through feedback, e.g. Prompting GPT-3 for Reliability
- Detection and mitigation of self-contradictions, e.g. ChatProtect
- Interactive improvement via feedback loops, e.g. Self-Reflection Methodology
C. Prompt Tuning
- Tuning instructions provided to models, e.g. UPRISE, SynTra
Developing Models category
A. New Decoding Strategies
- Guiding generation phase, e.g. Context-Aware Decoding
B. Utilization of Knowledge Graphs
- Injection of structured knowledge, e.g. RHO
C. Faithfulness Based Loss Functions
- Enhance factuality in outputs, e.g. THAM Framework
D. Supervised Fine-Tuning
- Tuning on labeled data, e.g. Knowledge Injection methods
Prompt Engineering category
A. Retrieval Augmented Generation (RAG)
- Before Generation: Strategies where information retrieval happens before text generation, e.g. LLM-Augmenter
- During Generation: Retrieval at sentence level generation, e.g. Knowledge Retrieval, D&Q Framework
- After Generation: Retrieval after full text generation, e.g. RARR
- End-to-End: Integrated retrieval and generation models, e.g. Original RAG model
B. Self-Refinement through Feedback and Reasoning
- Iterative refinement of outputs through feedback, e.g. Prompting GPT-3 for Reliability
- Detection and mitigation of self-contradictions, e.g. ChatProtect
- Interactive improvement via feedback loops, e.g. Self-Reflection Methodology
C. Prompt Tuning
- Tuning instructions provided to models, e.g. UPRISE, SynTra
Developing Models category
A. New Decoding Strategies
- Guiding generation phase, e.g. Context-Aware Decoding
B. Utilization of Knowledge Graphs
- Injection of structured knowledge, e.g. RHO
C. Faithfulness Based Loss Functions
- Enhance factuality in outputs, e.g. THAM Framework
D. Supervised Fine-Tuning
- Tuning on labeled data, e.g. Knowledge Injection methods
2/n Related to this is an ontology of prompting.
3/n As well as the emerging framework of prompt programming.
4/n As well as the various ways of integrating Knowledge Graphs with LLMs.
5/n Include an ontology of evaluation methods for LLMs.

Loading suggestions...