

K-Means is the simplest clustering algorithm.
Here is how it works 🔽
1/6
Here is how it works 🔽
1/6

The goal of K-Means is to find k groups in the data based on their similarities.
It's a form of unsupervised learning, so there are no predefined groups.
The model needs to figure them out itself.
Let's look at this example 👇
2/6
It's a form of unsupervised learning, so there are no predefined groups.
The model needs to figure them out itself.
Let's look at this example 👇
2/6
Consider our dataset as a map.
The empty space is the ocean and datapoints are forming continents.
The goal of K-Means is to find the centers of the continents.
Here is the breakdown step by step:
3/6
The empty space is the ocean and datapoints are forming continents.
The goal of K-Means is to find the centers of the continents.
Here is the breakdown step by step:
3/6

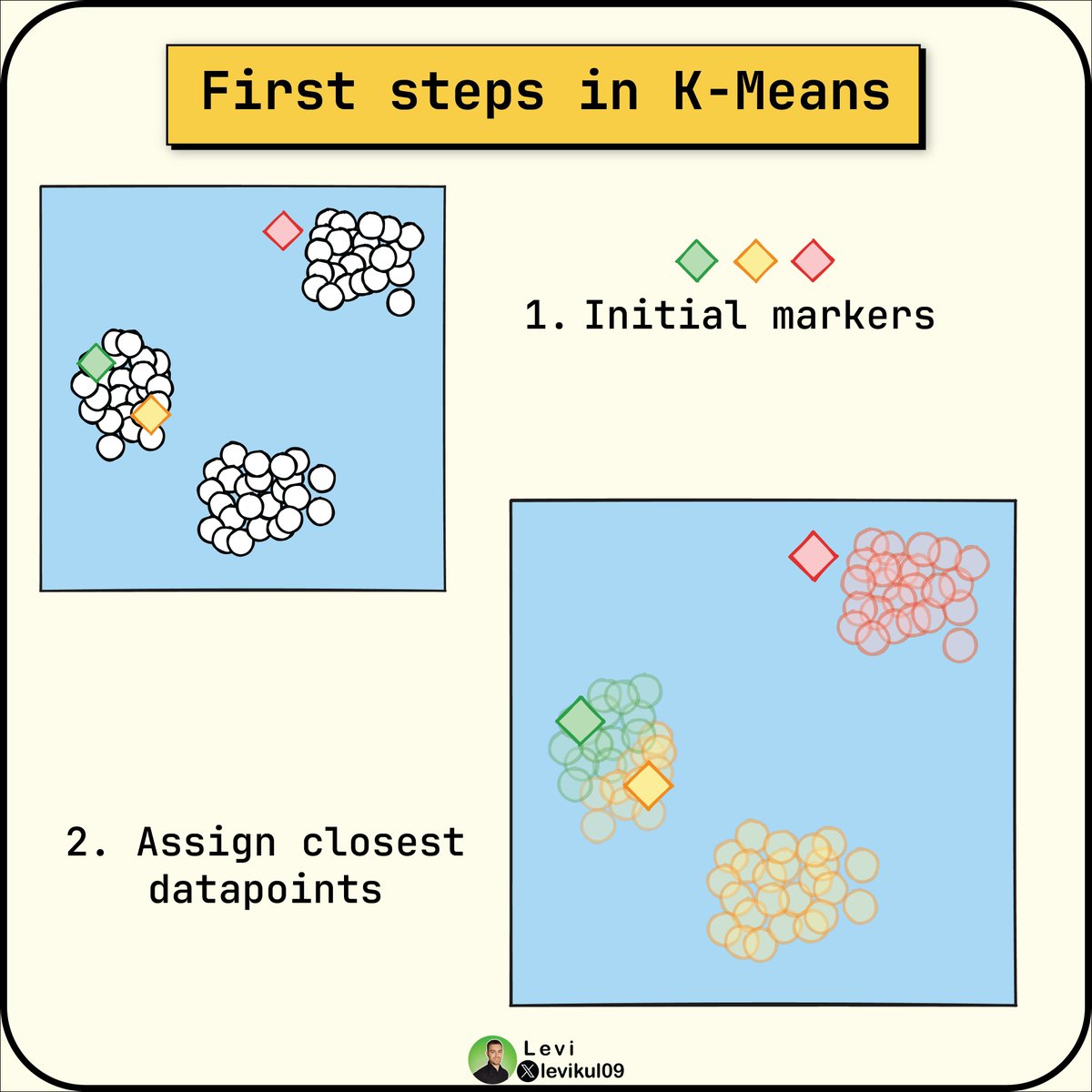
First, we randomly place some markers on the map.
(These markers are called centroids).
Then to each marker, we link the closest data points.
Since we are not close enough, we need an update.
4/6
(These markers are called centroids).
Then to each marker, we link the closest data points.
Since we are not close enough, we need an update.
4/6
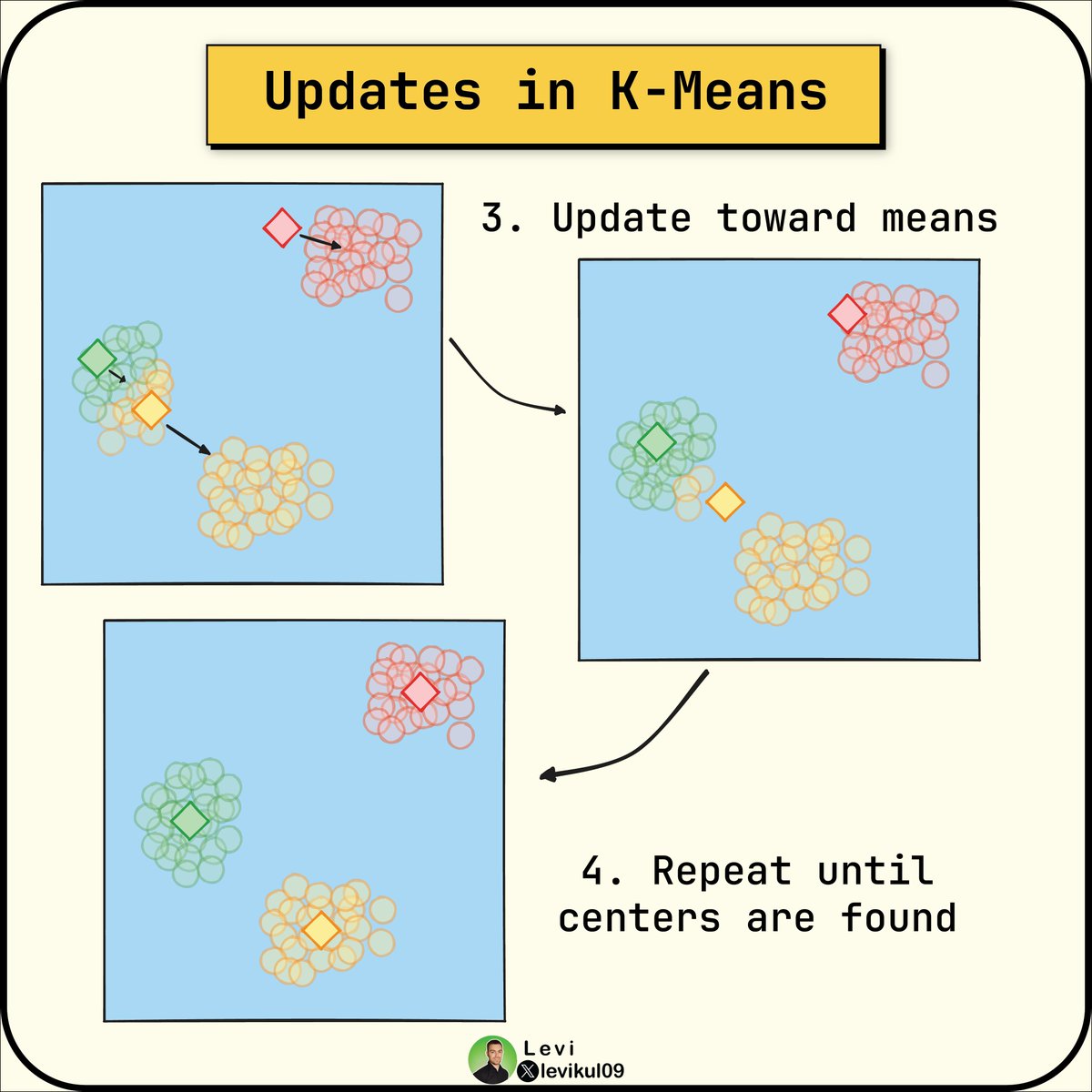
During the update, the markers are recalculated.
They are called centroids since they move towards the center.
It is typically the mean of all assigned data points.
This update is repeated several times until there is no meaningful change in the marker's position.
5/6
They are called centroids since they move towards the center.
It is typically the mean of all assigned data points.
This update is repeated several times until there is no meaningful change in the marker's position.
5/6
Some important things:
- Value of K is defined by you, so be careful. It can significantly impact the model.
- If the initial centroid is wrongly placed, the model may not reach the best positions.
- If the shape of data is not spherical, K-Means may be the wrong choice.
6/6
- Value of K is defined by you, so be careful. It can significantly impact the model.
- If the initial centroid is wrongly placed, the model may not reach the best positions.
- If the shape of data is not spherical, K-Means may be the wrong choice.
6/6
Did you like this post?
Hit that follow button for me and pay back with your support.
It literally takes 1 second for you but makes me 10x happier.
Thanks 😉
(Main source for this thread: Introduction to Machine Learning with Python by Andreas C. Müller and Sarah Guido)
Hit that follow button for me and pay back with your support.
It literally takes 1 second for you but makes me 10x happier.
Thanks 😉
(Main source for this thread: Introduction to Machine Learning with Python by Andreas C. Müller and Sarah Guido)
If you haven't already, join our newsletter DSBoost.
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev

Loading suggestions...