

How standardization affects your models?
🧵
🧵

We want to group people based on their height and weight.
The problem is that the way we measure these metrics is different:
- We use kg for weight and the samples are between 50kgs and 150kgs.
- For height we use meters, ranging from 1.50m to 2.00m.
The problem is that the way we measure these metrics is different:
- We use kg for weight and the samples are between 50kgs and 150kgs.
- For height we use meters, ranging from 1.50m to 2.00m.
As you can see the scaling is different.
The range for weight is 100, while only 0.5 for height.
When we try to group people (with distance-based models), the weight differences matter way more than height.
That is because of the difference in range.
The range for weight is 100, while only 0.5 for height.
When we try to group people (with distance-based models), the weight differences matter way more than height.
That is because of the difference in range.
I created a random dataset and visualized K-means clustering without standardization.
The model created 4 groups based on weight.
The groups are not impacted by height at all!
But we wanted to include both height and weight.
The solution? Standardize the data.
The model created 4 groups based on weight.
The groups are not impacted by height at all!
But we wanted to include both height and weight.
The solution? Standardize the data.

Standardization means that we adjust the metrics so that both weight and height are measured on the same scale.
This way, when we compare, a big change in weight is just as important as a big change in height.
This way, when we compare, a big change in weight is just as important as a big change in height.
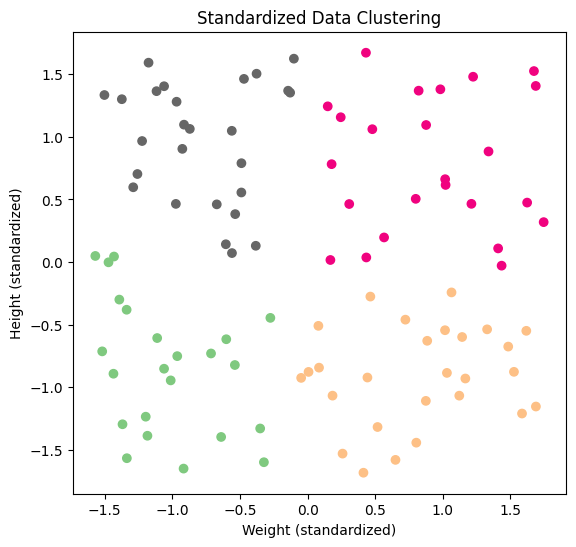
Here I standardized the data and applied the same K-means model to it.
As you can see, the model created 4 totally different groups.
Both weight and height are affecting the decision now.
That's because standardization brought the metrics to the same scale.
As you can see, the model created 4 totally different groups.
Both weight and height are affecting the decision now.
That's because standardization brought the metrics to the same scale.

Did you like this post?
Hit that follow button for me and pay back with your support.
It literally takes 1 second for you but makes me 10x happier.
Thanks 😉
Hit that follow button for me and pay back with your support.
It literally takes 1 second for you but makes me 10x happier.
Thanks 😉
If you haven't already, join our newsletter DSBoost.
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev
We share:
• Interviews
• Podcast notes
• Learning resources
• Interesting collections of content
dsboost.dev

Loading suggestions...