

Ok, here goes.
The mega implementation guide for FrugalGPT that can get you upto 98% cost savings on LLMs without compromising on accuracy.
I've written this over 6 months of research & iteration with what works and what doesn't - compressed into 3000 words for the web.
The mega implementation guide for FrugalGPT that can get you upto 98% cost savings on LLMs without compromising on accuracy.
I've written this over 6 months of research & iteration with what works and what doesn't - compressed into 3000 words for the web.

The paper's (by @ChenLingjiao, @matei_zaharia and @james_y_zou) summary is still one of the most viewed papers on the @PortkeyAI blog and I finally got the time through last week to compile all our notes on implementing this!
Big thanks to Lingjiao, Matei and James for publishing this paper and giving us a chance to explore concepts like these!
Big thanks to Lingjiao, Matei and James for publishing this paper and giving us a chance to explore concepts like these!
Read this as a blog with examples here - portkey.ai
Or thread below 👇🏻
Or thread below 👇🏻

The core of FrugalGPT revolves around three key techniques for reducing LLM inference costs:
- Prompt Adaptation - Using concise, optimized prompts to minimize prompt processing costs
- LLM Approximation - Utilizing caches and model fine-tuning to avoid repeated queries to expensive models
- LLM Cascade - Dynamically selecting the optimal set of LLMs to query based on the input
- Prompt Adaptation - Using concise, optimized prompts to minimize prompt processing costs
- LLM Approximation - Utilizing caches and model fine-tuning to avoid repeated queries to expensive models
- LLM Cascade - Dynamically selecting the optimal set of LLMs to query based on the input
1. Prompt Adaptation
FrugalGPT wants us to either reduce the size of the prompt OR combine similar prompts together. Core idea is to minimise tokens and thus reduce LLM costs.
1. Find only the best examples for few-shot prompts and reduce prompt token costs
FrugalGPT wants us to either reduce the size of the prompt OR combine similar prompts together. Core idea is to minimise tokens and thus reduce LLM costs.
1. Find only the best examples for few-shot prompts and reduce prompt token costs
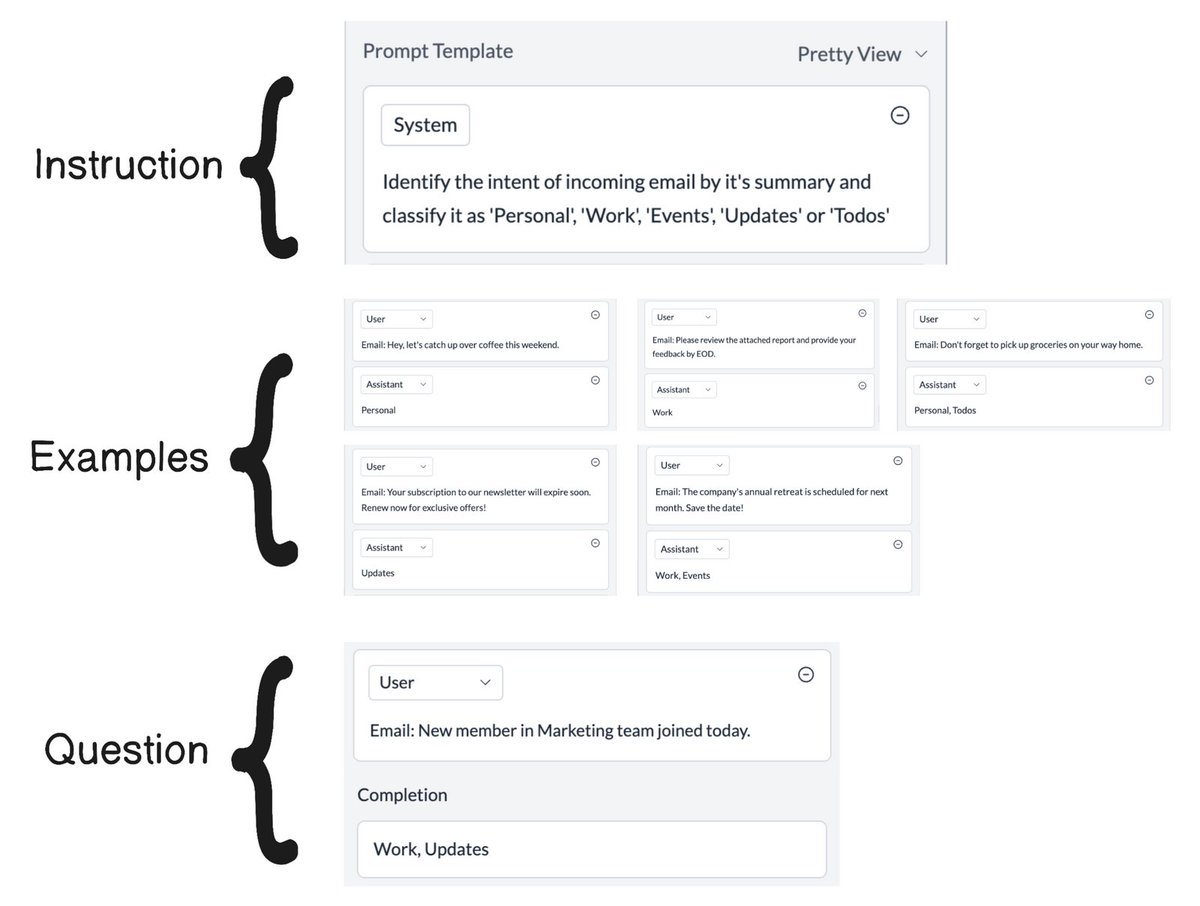
1.2 Combine similar requests together
LLMs have been found to retain context for multiple tasks together and FrugalGPT proposes to use this to group multiple requests together thus decreasing the redundant prompt examples in each request.
LLMs have been found to retain context for multiple tasks together and FrugalGPT proposes to use this to group multiple requests together thus decreasing the redundant prompt examples in each request.

1.3 Better utilize a smaller model with a more optimized prompt (h/t @mattshumer_ )
There may be certain tasks that can only be accomplished with bigger models. This is because prompting a bigger model is easier or also because you can write a more general purpose prompt, do zero-shot prompting without giving any examples, and still get reliable results.
There may be certain tasks that can only be accomplished with bigger models. This is because prompting a bigger model is easier or also because you can write a more general purpose prompt, do zero-shot prompting without giving any examples, and still get reliable results.

1.4 Compress the prompt
The LLMLingua paper published in April, 2024 talks about an interesting concept to reduce LLM costs called prompt compression. Prompt compression aims to shorten the input prompts fed into LLMs while preserving the key information, in order to make LLM inference more efficient and less costly.
The LLMLingua paper published in April, 2024 talks about an interesting concept to reduce LLM costs called prompt compression. Prompt compression aims to shorten the input prompts fed into LLMs while preserving the key information, in order to make LLM inference more efficient and less costly.
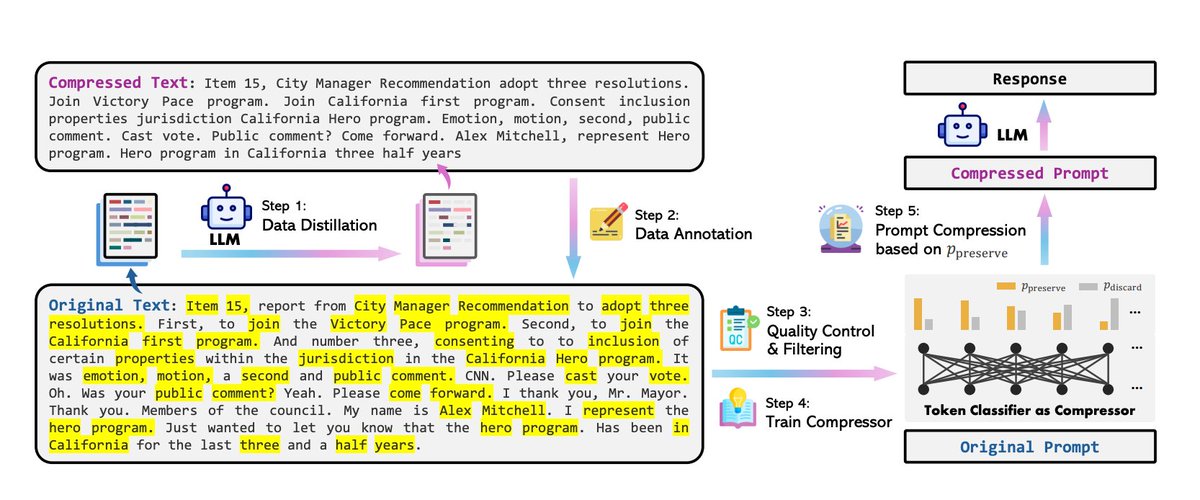
2. LLM Approximation
LLM approximation is another key strategy proposed in FrugalGPT for reducing the costs associated with querying large language models. The idea is to approximate an expensive LLM using cheaper models or infrastructure when possible, without significantly sacrificing performance.
2.1 Cache LLM Requests
The age-old technique to reduce costs, applies to LLM requests as well. When the prompt is exactly the same, we can save the inference time and cost by serving the request from cache.
At @PortkeyAI , we've seen that adding a cache to a co-pilot, on average results in 8% cache hits with 99% cost savings, along with a 95% decrease in latency.
LLM approximation is another key strategy proposed in FrugalGPT for reducing the costs associated with querying large language models. The idea is to approximate an expensive LLM using cheaper models or infrastructure when possible, without significantly sacrificing performance.
2.1 Cache LLM Requests
The age-old technique to reduce costs, applies to LLM requests as well. When the prompt is exactly the same, we can save the inference time and cost by serving the request from cache.
At @PortkeyAI , we've seen that adding a cache to a co-pilot, on average results in 8% cache hits with 99% cost savings, along with a 95% decrease in latency.

2.2 Fine-tune a smaller model in parallel
We know that switching to smaller models decreases inference cost and latency both. But, this is usually at the expense of accuracy. Fine-tuning is a very effective middle ground, where you can train a smaller model on a specific task and have it perform as well or even better than the larger model.
We know that switching to smaller models decreases inference cost and latency both. But, this is usually at the expense of accuracy. Fine-tuning is a very effective middle ground, where you can train a smaller model on a specific task and have it perform as well or even better than the larger model.

3. LLM Cascade
The LLM cascade is a powerful technique proposed in FrugalGPT that leverages the diversity of available LLMs to optimize for both cost and performance. The key idea is to sequentially query different LLMs based on the confidence of the previous LLM's response. If a cheaper LLM can provide a satisfactory answer, there's no need to query the more expensive models, thus saving costs.
The LLM cascade is a powerful technique proposed in FrugalGPT that leverages the diversity of available LLMs to optimize for both cost and performance. The key idea is to sequentially query different LLMs based on the confidence of the previous LLM's response. If a cheaper LLM can provide a satisfactory answer, there's no need to query the more expensive models, thus saving costs.
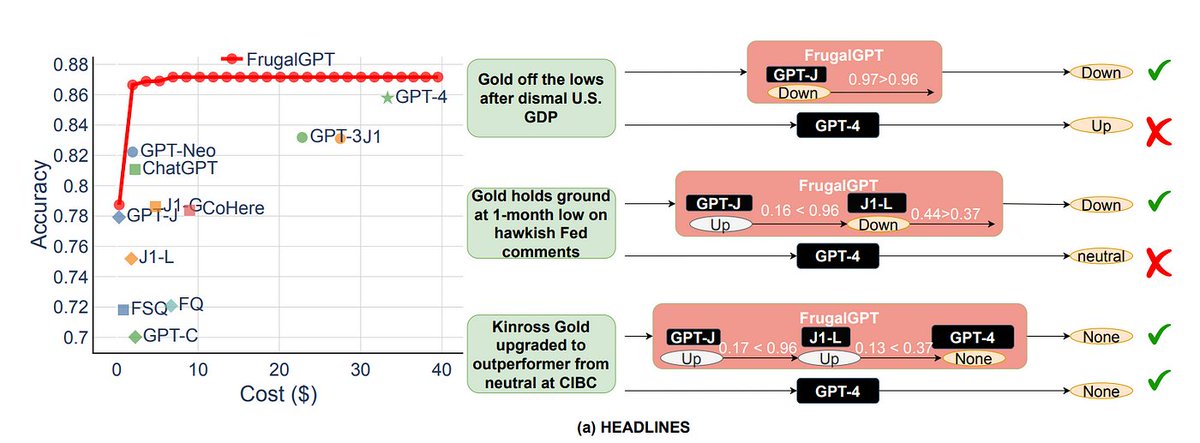
All together now!
In conclusion, FrugalGPT offers a comprehensive set of strategies for optimizing LLM usage while reducing costs and maintaining high performance. By implementing techniques such as prompt adaptation, LLM approximation, and LLM cascade, developers and businesses can significantly reduce their LLM operating expenses without compromising on the quality of their AI-powered applications.
In conclusion, FrugalGPT offers a comprehensive set of strategies for optimizing LLM usage while reducing costs and maintaining high performance. By implementing techniques such as prompt adaptation, LLM approximation, and LLM cascade, developers and businesses can significantly reduce their LLM operating expenses without compromising on the quality of their AI-powered applications.

Would love to hear from you how you've adopted FrugalGPT in your workflows or if you found something new here! 🙏🏻
Loading suggestions...