

Sliding Window Attention is such a brilliant idea 💡
And it was one of the secret sauces behind the legendary Mistral-7B, which enabled it to handle 100k+ token sequences with linear (ish) complexity.
A long thread 🧵1/n
---
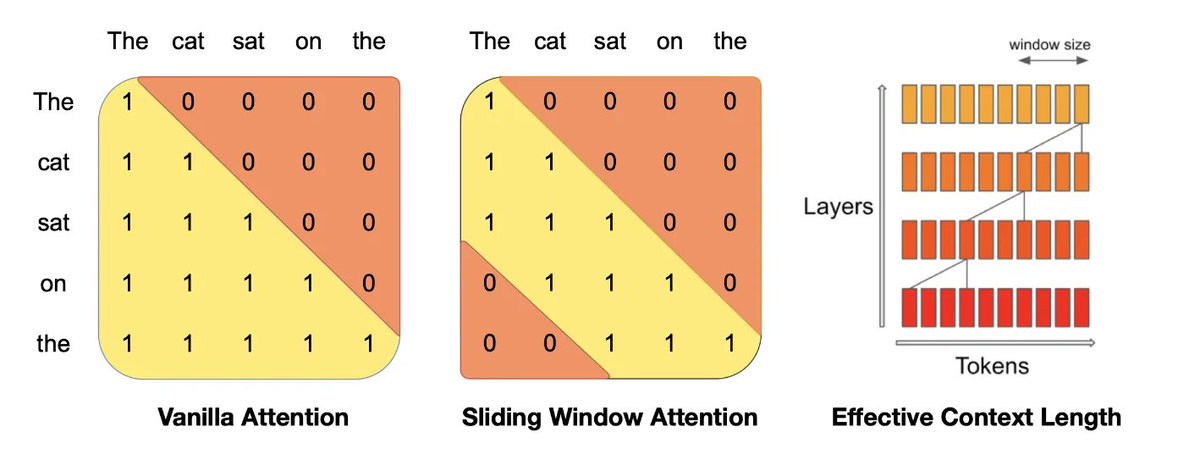
📌 Most Transformers use Vanilla Attention, where each token in the sequence can attend to itself and all the tokens in the past.
📌 So the memory increases linearly with the number of tokens. Hence the problem of higher latency during inference time and smaller throughput due to reduced cache availability.
📌 Sliding Window Attention (SWA) can alleviate those problems and can handle longer sequences of tokens more effectively at a reduced computational cost.
So standard, decoder-only, causal LMs (like the whole GPT series), each token can "attend to" (i.e. "look at") every token that has come before it.
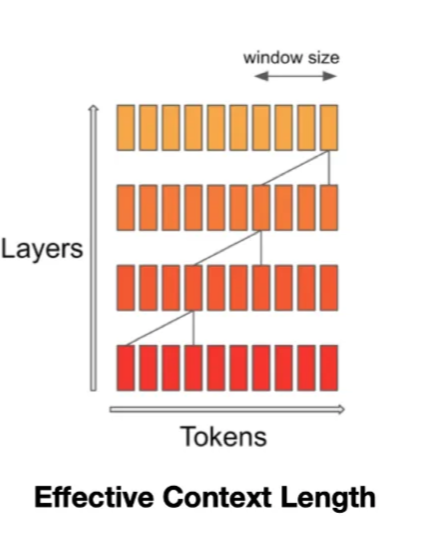
In Sliding Window Attention, earlier layers have a narrower view of history, and this progressively builds up the deeper you go into the model.
----
📌 Performance implications of sliding window attention:
Computational complexity: O(n * w) where n is sequence length, w is window size
Memory usage: O(w) instead of O(n) for full attention
Information retention: Local context preserved, global context approximated
----
📌 Because SWA exploits the stacked attention layers to attend information beyond the window size W.
📌 Each hidden state h in position i of layer k can attend to all hidden states from the previous layer with position between i-W and i. Where `W` is the "Window Size"
📌 This holds for all hidden states. Thus, recursively, a hidden state can access tokens from the input layer at a distance of W x k tokens. With 32 layers and a window size of 4096, this model has an attention span of 131k tokens.
----
📌 Limitations of Sliding Window Attention
Lack of Global Context − Because Sliding Window Attention operates on fixed windows, it may not be able to capture long-range dependencies that span across multiple windows. This can limit the model's ability to understand the global context of the input sequence.
📌 Example, if prompt/instruction text is 16K but Sliding Window Attention's sliding window is only 4K, it may cause my instructions to get ignored, as the window moved to the last 4K of those 16K and will "un-attend" my instructions at the beginning of those 16K.
----------
📌 Global Attention, in contrast, considers the entire input sequence at once, applying attention to all positions simultaneously. It focuses on specific, strategically chosen locations to capture the most relevant information, ensuring that each token with global attention is connected to every other token in the sequence. While Global Attention provides a comprehensive view of the sequence context, it can significantly increase computational demands.
📌 Combining SWA with Global Attention, as seen in architectures like Longformer, offers a balanced approach. This hybrid method maintains efficiency while ensuring the model captures both local and global sequence context, crucial for accurate performance on tasks with long input sequences.
And it was one of the secret sauces behind the legendary Mistral-7B, which enabled it to handle 100k+ token sequences with linear (ish) complexity.
A long thread 🧵1/n
---
📌 Most Transformers use Vanilla Attention, where each token in the sequence can attend to itself and all the tokens in the past.
📌 So the memory increases linearly with the number of tokens. Hence the problem of higher latency during inference time and smaller throughput due to reduced cache availability.
📌 Sliding Window Attention (SWA) can alleviate those problems and can handle longer sequences of tokens more effectively at a reduced computational cost.
So standard, decoder-only, causal LMs (like the whole GPT series), each token can "attend to" (i.e. "look at") every token that has come before it.
In Sliding Window Attention, earlier layers have a narrower view of history, and this progressively builds up the deeper you go into the model.
----
📌 Performance implications of sliding window attention:
Computational complexity: O(n * w) where n is sequence length, w is window size
Memory usage: O(w) instead of O(n) for full attention
Information retention: Local context preserved, global context approximated
----
📌 Because SWA exploits the stacked attention layers to attend information beyond the window size W.
📌 Each hidden state h in position i of layer k can attend to all hidden states from the previous layer with position between i-W and i. Where `W` is the "Window Size"
📌 This holds for all hidden states. Thus, recursively, a hidden state can access tokens from the input layer at a distance of W x k tokens. With 32 layers and a window size of 4096, this model has an attention span of 131k tokens.
----
📌 Limitations of Sliding Window Attention
Lack of Global Context − Because Sliding Window Attention operates on fixed windows, it may not be able to capture long-range dependencies that span across multiple windows. This can limit the model's ability to understand the global context of the input sequence.
📌 Example, if prompt/instruction text is 16K but Sliding Window Attention's sliding window is only 4K, it may cause my instructions to get ignored, as the window moved to the last 4K of those 16K and will "un-attend" my instructions at the beginning of those 16K.
----------
📌 Global Attention, in contrast, considers the entire input sequence at once, applying attention to all positions simultaneously. It focuses on specific, strategically chosen locations to capture the most relevant information, ensuring that each token with global attention is connected to every other token in the sequence. While Global Attention provides a comprehensive view of the sequence context, it can significantly increase computational demands.
📌 Combining SWA with Global Attention, as seen in architectures like Longformer, offers a balanced approach. This hybrid method maintains efficiency while ensuring the model captures both local and global sequence context, crucial for accurate performance on tasks with long input sequences.

🧵2/n
📌 Common misconceptions about sliding window attention:
* It completely discards all information from earlier tokens
* Linear complexity means no performance trade-offs
* It's always better than full attention for all tasks
📌 Common misconceptions about sliding window attention:
* It completely discards all information from earlier tokens
* Linear complexity means no performance trade-offs
* It's always better than full attention for all tasks
🧵3/n
📌 Information loss mitigation strategies:
1. Overlapping windows: Retain some information from previous windows
2. Sparse global attention: Allow select tokens to attend globally
3. Hierarchical structures: Capture long-range dependencies at higher levels
📌 Information loss mitigation strategies:
1. Overlapping windows: Retain some information from previous windows
2. Sparse global attention: Allow select tokens to attend globally
3. Hierarchical structures: Capture long-range dependencies at higher levels
🧵4/n
📌 How Mistral was so effective despite sliding window:
1. Careful window size selection: Balances context retention and efficiency
2. Advanced positional embeddings: Enhance relative position understanding
3. Architecture optimizations: Deeper layers, increased model capacity
4. Task-specific fine-tuning: Adapt to required context lengths
📌 How Mistral was so effective despite sliding window:
1. Careful window size selection: Balances context retention and efficiency
2. Advanced positional embeddings: Enhance relative position understanding
3. Architecture optimizations: Deeper layers, increased model capacity
4. Task-specific fine-tuning: Adapt to required context lengths
🧵5/n
📌 Sliding window benefits beyond computational efficiency:
1. Improved handling of streaming inputs
2. Reduced overfitting on position-based patterns
3. Better generalization to variable-length sequences
4. More efficient training on longer contexts
📌 Sliding window benefits beyond computational efficiency:
1. Improved handling of streaming inputs
2. Reduced overfitting on position-based patterns
3. Better generalization to variable-length sequences
4. More efficient training on longer contexts
🧵6/n
📌 Attention matrix comparison:
Vanilla: Lower triangular matrix, all tokens attend to previous
Sliding Window: Diagonal band pattern, limited context window
📌 Sliding Window specifics:
Window size: 3 tokens (visible from diagonal band width)
Tokens attend only to 2 previous + current token
Zeros in upper-left and lower-right corners indicate no attention
📌 Context reduction:
"the" (last token): Attends to "on", "sat", "the" only
"on" (4th token): Cannot see "The" (1st token)
Information from earlier tokens not directly accessible
📌 Effective context length visualization:
Right-side diagram shows layered approach
Each layer has fixed window size (orange bars)
Deeper layers indirectly access wider context
Total effective context increases with depth
📌 Computational implications:
Reduced operations per token: O(w) vs O(n)
Memory usage: Constant per layer vs growing with sequence
📌 Information flow:
Local patterns captured effectively
Global context built hierarchically through layers
Trade-off: Efficiency vs immediate full-sequence context
📌 Adaptation considerations:
Window size crucial for performance-context balance
Model depth impacts effective context length
Task-specific tuning may be needed for optimal results
📌 Attention matrix comparison:
Vanilla: Lower triangular matrix, all tokens attend to previous
Sliding Window: Diagonal band pattern, limited context window
📌 Sliding Window specifics:
Window size: 3 tokens (visible from diagonal band width)
Tokens attend only to 2 previous + current token
Zeros in upper-left and lower-right corners indicate no attention
📌 Context reduction:
"the" (last token): Attends to "on", "sat", "the" only
"on" (4th token): Cannot see "The" (1st token)
Information from earlier tokens not directly accessible
📌 Effective context length visualization:
Right-side diagram shows layered approach
Each layer has fixed window size (orange bars)
Deeper layers indirectly access wider context
Total effective context increases with depth
📌 Computational implications:
Reduced operations per token: O(w) vs O(n)
Memory usage: Constant per layer vs growing with sequence
📌 Information flow:
Local patterns captured effectively
Global context built hierarchically through layers
Trade-off: Efficiency vs immediate full-sequence context
📌 Adaptation considerations:
Window size crucial for performance-context balance
Model depth impacts effective context length
Task-specific tuning may be needed for optimal results
🧵 7/n
👨🔧 Layered attention mechanism:
In SWA, the hidden state at position i in layer k can attend to hidden states from the preceding layer within the range of positions i — W to i, allowing access to tokens at a distance of up to W * k tokens. By employing a window size of W = 4096, SWA theoretically achieves an attention span of approximately 131K tokens.
32 layers * 4096 window ≈ 131K tokens
👨🔧 In practice with a sequence length of 16K and W = 4096, SWA modifications in FlashAttention and xFormers result in a 2x speed enhancement compared to vanilla attention methods.
👨🔧 Layered attention mechanism:
In SWA, the hidden state at position i in layer k can attend to hidden states from the preceding layer within the range of positions i — W to i, allowing access to tokens at a distance of up to W * k tokens. By employing a window size of W = 4096, SWA theoretically achieves an attention span of approximately 131K tokens.
32 layers * 4096 window ≈ 131K tokens
👨🔧 In practice with a sequence length of 16K and W = 4096, SWA modifications in FlashAttention and xFormers result in a 2x speed enhancement compared to vanilla attention methods.
Loading suggestions...